5 Introducción al análisis multivariado de datos BEA
5.1 Análisis tipo Q y tipo R
El análisis multivariado de las matrices BEA puede abordarse desde dos perspectivas fundamentales: se puede optar por investigar las relaciones entre los descriptores (análisis en modo R) o las relaciones entre los objetos (análisis en modo Q). Es importante destacar que estos enfoques de análisis se apoyan en diferentes aproximaciones cuantitativas, pero sobre todo conceptuales (figura 5.1). Por ejemplo, cuando interesa evaluar la relación entre varias variables ambientales a lo largo de un gradiente espacial o serie temporal, estaríamos en modo R. En este caso, la evaluación se lleva a cabo mediante análisis de covarianza o correlación, y contempla la ejecución de procedimientos de álgebra matricial con las restricciones discutidas en el segmento anterior. Similarmente, cuando interesa evaluar la co-ocurrencia de especies a lo largo de un gradiente espacial, la relación entre las variables debe hacerse con métodos de correlación especiales para matrices inflados con valores 0. En ambos casos, el interés principal son las variables, no los objetos.
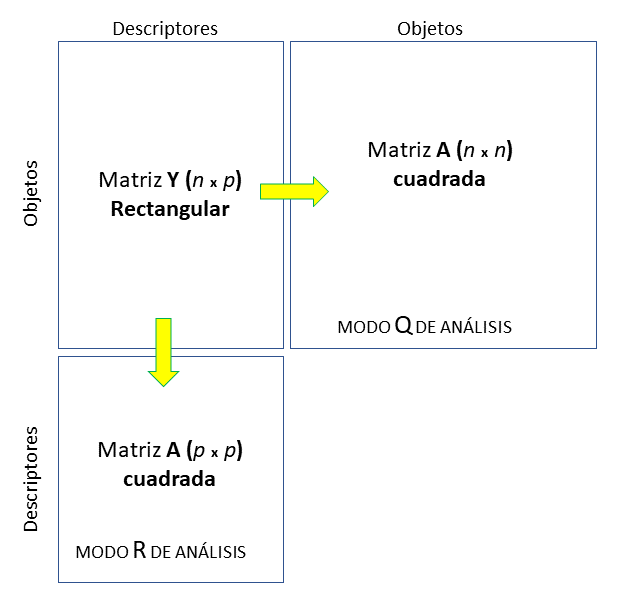
Por otro lado, el análisis en modo Q se centra en descubrir relaciones entre objetos usando medidas de distancia o similitud. Más allá de tener interés sobre la relación específica de las variables, interesa evaluar la relación entre los objetos; por ejemplo, comparar las variaciones en la composición de especies o las variaciones de característica ambientales de lugares contaminados respecto a reservas naturales. Estos son los análisis más comunes en ciencias ecológicas y ambientales. Esta guía de estudio se centrará fundamentalmente en describir aproximaciones multivariadas de modo Q.
5.2 Análisis en modo Q
Estos análisis incluyen varias técnicas de las que destacan los gráficos que representan la relación entre los objetos (en adelante ordenaciones) y las pruebas estadísticas sobre modelos específicos (en adelante pruebas). Son varias las alternativas de ordenaciones, así como varias las alternativas de pruebas. En ambos casos, se pueden representar y evaluar modelos simples de un solo factor, hasta modelos más complejos, incluyendo diseños experimentales multifactoriales, de efectos mixtos, series de tiempo multivariada, etc. No obstante, lo más importante que se debe tener en cuenta es que estos análisis son fuertemente dependientes del tratamiento matempatico que se haya aplicado a los datos BEA originales (ver Sección 3.2), así como de la medida de asociación empleada.
Las medidas de asociación para los análisis en modo Q se dividen en dos: coeficientes de distancia y coeficientes de similitud. Los primeros miden las diferencias entre dos objetos en función de una métrica de distancia geométrica, mientras que los coeficientes de similitud miden la similitud (o disimilitud) entre dos objetos en función de alguna medida de asociación. En términos de escala, los coeficientes de distancia generalmente varían de 0 a infinito, con 0 indicando que los objetos son idénticos y valores mayores indicando una mayor diferencia. La unidad de la distancia suele no tener interpretación. Por otro lado, los coeficientes de similitud varían de 0 a 1 (o 100), con 1 (o 100) indicando que los objetos son idénticos y valores más bajos indicando una menor similitud, hasta 0 que representa completa diferencia. Sus unidades sí suelen tener significado en términos relativos, dependiendo del coeficiente empleado. Es importante destacar que una medida de disimilitud puede interpretarse esencialmente como el complemento de la similitud, donde la disimilitud entre dos objetos es igual a 1 menos la similitud entre ellos.
Otra diferencia relevante entre los coeficientes de similitud y distancia radica en el efecto de los dobles ceros. Es decir, si en la ecuación del coeficiente se considera la doble ausencia de un descriptor, entonces el coeficiente se reconoce como simétrico. Todos los coeficientes de distancia son simétricos. Por otra parte, si en la ecuación del coeficientes se ignora la ausencia de un descriptor en ambos objetos que están siendo comparados, entonces el coeficiente es asimétrico. La ausencia o presencia de un descriptor en la asociación de dos objetos se puede resumir en una tabla de frecuencia 2⨯2:
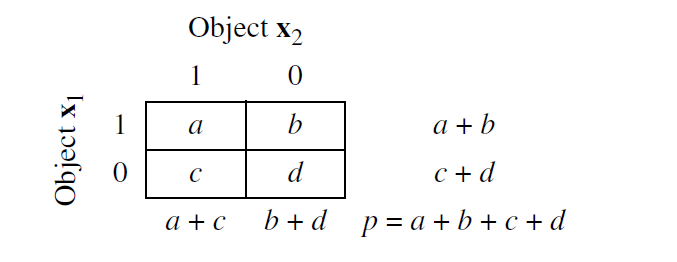
donde a indica el número de descriptores presentes en ambas muestras, b y c representan el número de descriptores presentes en una muestra pero no en la otra, y d al número de descriptores con valor cero en ambas muestras.
En el caso de datos ecológicos, si el muestreo se realizó a lo largo de un gradiente ambiental, las especies pueden variar drásticamente de un extremo a otro. Usar algún coeficiente de asociación que incluya a d en su ecuación implicará que la comparación entre sitios genere valores de similitud elevados para pares de sitios con pocas especies comunes pero con muchas doble ausencias. Por lo tanto, al analizar datos de presencia/ausencia o abundancia de especies, los ecólogos suelen optar por coeficientes asimétricos (Clarke (1993)). Contrariamente, en matrices ambientales, el doble 0 puede tener mucho significado, ya que no se trata de que la variable estuvo ausente en dos muestras, sino de variables cuyo 0 tiene un significado en la escala (p. ej. salinidad, concentración de oxígeno, o concentración de algún contaminante). En estos casos, la doble ausencia indica que los sitios se parecen en esa condición ambiental peculiar, e interesa que sean asociados por coincidir en esas variables. Entonces, para datos ambientales, usar algún coeficiente de similitud simétrico o alguna medida de distancia es lo ideal.
Bien sea con distancias o con similitudes simétricas o asimétricas, con ambos tipos de coeficientes se pueden analizar matrices binarias y cuantitativas. Por binaria se hace referencia a matrices cuyos descriptores solo tienen valores 1 (presente) y 0 (ausente); también se le conocen como matrices de incidencia o matrices presencia/ausencia. Por cuantitativas se hace referencia a matrices en que cada descriptor presenta cifras que representan de alguna manera la magnitud con que se expresó esa variable. En ambos casos, la aplicación de un coeficiente de distancia o similitud a una matriz A con tamaño P ⨯ N, implicará la generación de una matriz triangular con dimensiones N ⨯ N, en el que cada celda representará la medida de distancia, disimilitud o similitud en cada par de objetos.
Otra característica que distingue a las distancias de los coeficientes de similitud es que las distancias son siempre métricas, mientras que los coeficientes de similitud nunca son métricos, pero pueden ser semi-métricos. Para que un coeficiente sea considerado métrico debe cumplir con las siguientes propiedades:
Positividad: La distancia entre dos puntos es siempre mayor o igual a cero, es decir, \(d(x, y) \geq 0\), y solo es igual a cero si y solo si los puntos son idénticos.
Simetría: La distancia entre dos puntos es la misma independientemente del orden en el que se consideren, es decir, \(d(x, y) = d(y, x)\).
Identidad de indiscernibles: La distancia entre un punto y sí mismo es siempre cero, es decir, \(d(x, x) = 0\).
Desigualdad del triangulo: La distancia entre dos puntos es siempre menor o igual a la suma de las distancias de esos dos puntos a un tercer punto, es decir, \(d(x, z) \leq d(x, y) + d(y, z)\). Esta propiedad es esencialmente una versión generalizada del teorema de Pitágoras, pero se aplica a cualquier tipo de triángulo, no solo a los triángulos rectángulos.
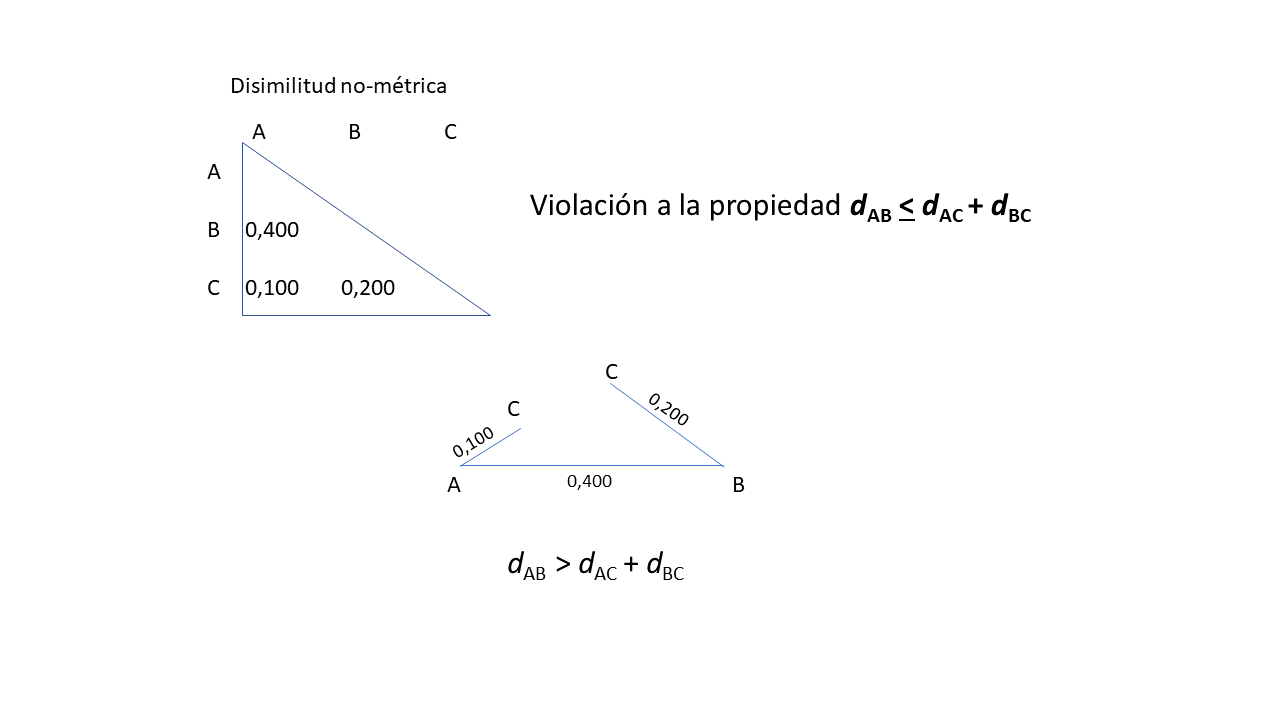
La mayoría de los coeficientes de similitud cumplen las tres primeras propiedades pero rara vez cumplen con la desigualdad del triangulo. Es por esta razón que varios coeficientes de similitud son considerados semi-métricos. La repercusión de esto es que no es posible proyectar objetos asociados con un coeficiente no métrico o semimétrico en un espacio métrico o euclidiano. Como se aprecia en la figura 5.2, la relación entre los objetos A, B y C se estimó con una medida no métrica, al tratar de proyectarlos en un plano (por ser tres objetos solo se requiere un plano para proyectarlos) se notará que no se puede satisfacer la desigualdad del triangulo ya que el objeto C requeriría estar simultánemente en dos puntos del plano para poder satisfacer la relación no-métrica. Más adelante veremos que esto se reflejará en procedimientos muy importantes como los Análisis de Coordenadas Principales (PCO por sus siglas en inglés), pero no repercutirá en la interpretación que se pueda hacer de la ordenación o prueba estadística.
5.2.1 Coeficientes de distancia
Estos se han desarrollado principalmente para analizar matrices cuantitativas, pero ocasionalmente se han utilizado con descriptores semicuantitativos. Algunas de estas medidas (como la Euclidiana y Manhattan) procesan los dobles ceros de la misma manera que cualquier otro valor de los descriptores; por lo tanto, no deben usarse para analizar matrices ecológicas, pero sí pueden ser usados (y son ideales) para analizar matrices ambientales y biológicas. No obstante, hay distancias como la Chord que presentan modificaciones particulares en que los doble-cero no influyen y sí podrían usarse con matrices ecológicas. En líneas generales, se pueden contabilizar al menos 16 coeficientes de distancia para análisis en modo Q en el libro Numerical Ecology (Legendre y Legendre 2012), del que vamos a destacar tres:
- Distancia Euclidiana:
Se calcula utilizando la fórmula de Pitágoras, a partir de puntos ubicados en un espacio p-dimensional llamado espacio métrico o euclidiano:
\[\begin{equation} D_1 (x_1,x_2) = \sqrt{ \sum_{j = 1}^{p}(y_{1j} - y_{2j})^2} \end{equation}\]
donde \(y_{1j}\) y \(y_{2j}\) representan la magnitud de la j-ésima variable en los objetos \(x_{1}\) y \(x_{2}\), respectivamente. La distancia euclidiana no tiene límite superior, además, a medida que aumente el número de descriptores también aumentará indefinidamente su magnitud. Por esta razón las magnitudes euclidianas no son interpretables o comparables entre estudios, más allá de la proyección geométrica. El valor también depende de la escala de cada descriptor: noten en la ecuación que se trata de una sumatoria de diferencias, y evidentemente los descriptores con unidades de mayor magnitud dominarán la sumatoria. Para evitar esto, se puede aplicar normalización (centrar en cero las variables) a los datos, tal como se recomendó en Sección 3.2.
- Distancia Manhattan
En el supuesto de dos descriptores, la distancia Manhattan entre dos objetos es la distancia perpendicular entre la abscisa (descriptor \(y_1\)) más la distancia en la ordenadas (descriptor \(y_2\)). Esto es el equivalente a la distancia recorrida por una persona caminando alrededor de un edificio al que no puede entrar, y requiere llegar de la esquina 1 (de 4 en una cuadra) a la esquina 3. Esta métrica presenta el mismo problema para doble ceros que en la distancia euclidiana. Su ecuación es:
\[\begin{equation} D_7 (x_1,x_2) = \sum_{j = 1}^{p}|y_{1j} - y_{2j}| \end{equation}\]
- Distancia Chord
Es una medida de distancia utilizada en la teoría de grafos para cuantificar la diferencia entre dos nodos en un grafo. Se define como la longitud del camino más corto entre dos nodos, considerando únicamente los arcos que conforman un ciclo que conecta ambos nodos. Esta distancia tiene un valor máximo de \(\sqrt{2}\) para objetos sin descriptores en común y un mínimo de 0 cuando dos objetos comparten los mismos descriptores en las mismas proporciones, sin que sea necesario que estos descriptores esten representados por las mismas magnitudes. Esta medida es equivalente a la distancia Euclidiana aplicada después de estandarizar los vectores a una longitud 1. Después de la estandarización, la distancia Euclidiana calculada entre dos objetos será equivalente a la longitud de una cuerda que une dos puntos dentro de un segmento de una esfera o hiperesfera de radio 1. La distancia Chord se puede calcular directamente a partir de datos no estandarizados mediante la siguiente fórmula:
\[\begin{equation} D_3 (x_1,x_2) = \sqrt{2\left(1-\frac{\sum_{j = 1}^{p}y_{1j} y_{2j}}{\sqrt{\sum_{j = 1}^{p}y^2_{1j}\sum_{j = 1}^{p}y^2_{2j}}}\right)} \end{equation}\]
5.2.2 Coeficientes de similitud
Fueron desarrollados inicialmente para comparar matrices binarias, pero rápidamente se adaptaron para matrices cuantitativas. En la literatura existen una larga lista de medidas de similitud, cada una con propiedades muy peculiares sobre el peso particular de que le da a los indicadores compartidos, los no compartidos y los ausentes. Como ya se describió arriba, la mayor diferencia está en el tratamiento que se le da a los doble cero. Una lista detallada de las medidas de similitud se describe en el libro Numerical Ecology (Legendre y Legendre 2012). Acá nos centraremos en los que consideramos son las cuatro medidas más importantes y útiles para aplicar en ciencias biológicas, ecológicas y ambientales.
- Coeficiente de Gower
Es de los pocos coeficientes de similitud que puede asociar objetos combinando diferentes tipos de variables y procesarlas según su sea binaria, cualitativa y cuantitativa. Esta opción es particularmente útil para datos biológicos. La similitud entre dos objetos se obtiene con el promedio de similitudes parciales s sobre los p descriptores. La forma mas simple de Gower se estima con:
\[\begin{equation} S_{15}(x_1,x_2) = \frac{1}{p}\sum_{j = 1}^{p}s_{12j} \end{equation}\]
Para cada variable j, el valor de similitud parcial \(s_{12j}\) entre los objetos \(x_1\) y \(x_2\) se calcula de la siguiente manera:
Variables binarias: Si el descriptor está presente en ambos objetos, entonces \(s_j\) = 1, de lo contrario \(s_j\) = 0. Este índice tiene su versión métrica (\(S_{15}\)), en la que si los dos descriptores están ausentes implica \(s_j\) = 1, mientras que la versión asimétrica (\(S_{19}\)) asigna a la doble ausencia \(s_j\) = 0.
Variables cualitativas: Al igual que las binarias, si el descriptor está presente en ambos objetos, entonces \(s_j\) = 1, de lo contrario \(s_j\) = 0. La versión métrica \(S_{15}\) y asimétrica \(S_{19}\) también distinguen a los doble cero.
Variables cuantitativas: Para cada descriptor, primero se calcula la diferencia entre las magnitudes en ambos objetos. Luego, este valor se divide por la diferencia más grande (\(R_j\)) encontrada para este descriptor en todos los sitios del estudio. Dado que esta relación es en realidad una distancia estandarizada, se resta de 1 para transformarla en una similitud:
\[\begin{equation} S_{12j} = 1-[|y_{1j}-y_{2j}|/R_j] \end{equation}\]
A la propuesta original de Gower (del año 1971), Legendre y Legendre (2012) propusieron incorporar ponderadores para los descriptores según interese en el análisis. Habrá un multiplicador w para cada j descriptor (\(w_j\)) con valores de 0 hasta 1, correspondiente al peso que se desee tenga el descriptor en el análisis. Es decir, un ponderador cercano a 0 implicará que esa variable tendrá poco peso en la similitud, mientras que aquél con ponderador cercano o igual a 1 aportarán más a la similitud. Un valor faltante automáticamente convierte a \(w_j\) a 0. Con esto, la ecuación completa de \(S_{15}\) se expresan como:
\[\begin{equation} S_{15}(x_1,x_2) = \frac{\sum_{j = 1}^{p}w_{12j}s_{12j}}{\sum_{j = 1}^{p}w_{12j}} \end{equation}\]
La versión asimétrica (\(S_{19}\)) en esencia es la misma ecuación, solo que para aquellos descriptores ausentes en el par de objetos que están siendo comparados se asigna \(w_j\) = 0.
- Coeficiente de Jaccard
Es el índice de similitud binario más usado en ecología para comparar composición de especies y estimar 𝛽 diversidad. Propuesto a inicios del siglo XX, es una métrica que relativiza la cantidad de información compartida entre dos objetos, que en estudios ecológicas nos indica el porcentaje de especies compartidas entre dos muestra o sitios. Se obtiene con la ecuación:
\[\begin{equation} S_{7}(x_1,x_2) = \frac{a}{a+b+c} \end{equation}\]
donde a representa el número de especies presentes en ambas muestras, b y c representan el número de especies presentes en una muestra pero no en la otra. Note la doble ausencia p no forma parte de la ecuación, lo que hace del coeficiente de Jaccard un coeficiente asimétrico. En efecto, \(S_7\) se puede interpretar como la probabilidad de que una especie elegida al azar esté presente en ambas muestras. También note que a, b y c tienen el mismo peso, a diferencia del otro coeficiente muy usado, Sorensen, en que a tiene el doble del peso:
\[\begin{equation} S_{8}(x_1,x_2) = \frac{2a}{2a+b+c} \end{equation}\]
- Coeficiente de Bray-Curtis
Es uno de los coeficientes más usados, si no el más usado, en estudios ecológicos (Clarke et al. 2014). El coeficiente estima la similitud entre un par de objetos con la ecuación:
\[\begin{equation} S_{17}(x_1,x_2) = 100\left(1-\frac{\sum_{j = 1}^{p}|y_{1j}-y_{2j}|}{\sum_{j = 1}^{p}(y_{1j}+y_{2j})}\right) \end{equation}\]
acá también \(y_{1j}\) y \(y_{2j}\) representan la magnitud de la j-ésima variable en los objetos \(x_{1}\) y \(x_{2}\).
Tal como lo describe Clarke et al. (2014), las propiedades más importantes de Bray-Curtis para analizar datos ecológicos son:
Si las dos muestras no tienen especies en común, el coeficiente resultará en 0. Si la composición y abundancia de las especies es la misma, entonces |\(y_{1j}\) - \(y_{2j}\)| = 0 para cada j, entonces el coeficiente resultará en 100 (100 % de similitud)
Un cambio de escala en las medidas no cambiará el valor de similitud. Por ejemplo, la biomasa podría expresarse en g en lugar de mg. En estos casos, todos los valores de \(y\) se multiplican por la misma constante y esto se cancela en los términos del numerador y denominador de la ecuación.
El coeficiente es asimétrico, es decir, las dobles 0 no afectan la estimación de la similitud.
La incorporación o eliminación de una tercer muestra, digamos C, no afecta al cálculo de similitud entre A y B. Muchos coeficientes son sensibles a este punto ya que incluyen algún tipo de estandarización de las variables respecto a todas las muestras.
Permite registrar diferencias en el total de abundancia para dos muestras independientemente de que las abundancias relativas de todas las especies sean idénticas entre ambas muestras (algunos coeficientes se estandarizan automáticamente por totales, por lo que no puede reflejar estos cambios en totales).
5.3 Plan de trabajo para el uso de análisis multivariados
En el análisis modo Q o R, las similitudes o distancias que se calculan entre cada par de muestras o descriptores generarán una matriz triangular con tamaño N(N–1)/2. Estas matrices triangulares son la base de la mayoría de los métodos multivariados aplicados en biología, ecología y ciencias ambientales. La importancia de aplicar los tratamientos matemáticos adecuados a los datos, así como elegir el coeficiente de similitud o distancia pertinente para la pregunta, es lo más crítico del análisis. Cualquier método o procedimiento analítico que se decida aplicar dependerá de las decisiones previas se tomaron. Una vez construidas las matrices de similitud, estas se podrán utilizar para:
Discriminar sitios, tratamientos, tiempos, etc., entre sí, observando que las similitudes entre réplicas dentro de un sitio/tratamiento/tiempo son consistentemente mayores que las similitudes entre réplicas en diferentes sitios/tratamientos/tiempos (pruebas ANOSIM, MANOVA, PERMANOVA);
Agrupar muestras en grupos que tienen caracteristicas multivariadas similares, de modo que las similitudes dentro de cada grupo suelen ser mayores que las que existen entre los grupos (Análisis de clasificación);
Permitir representar gráficamente una gradación de muestras, en el caso de que las muestras A tenga alguna similitud con las muestras B, B con C, C con D pero A y C sean menos similares, A y D aún menos, etc. (Ordenaciones).
Construir modelos estadísticos explicativos sobre los cambios en la estructura multivariada de una matriz BEA según cambios en un vector o matriz multivariada.
Cada una da las alternativas para estos propósitos se irán incorporando con literatura actualizada, así como con los códigos en R necesarios para su comprensión e implementación.