Código
macrofauna <- datos[,3:length(datos)]Volvemos al estudio publicado por Gray JS, Clarke KR, Warwick RM, Hobbs G (1990). Detection of initial effects of pollution on marine benthos: an example from the Ekofisk and Eldfisk oilfields, North Sea. Marine Ecology Progress Series 66, 285-299.
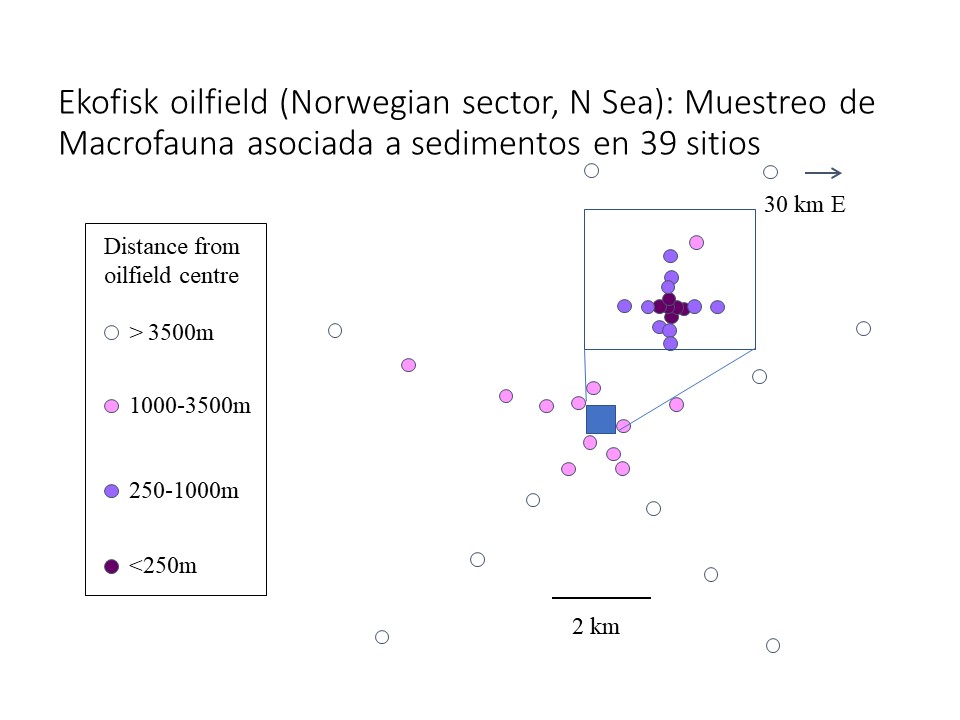
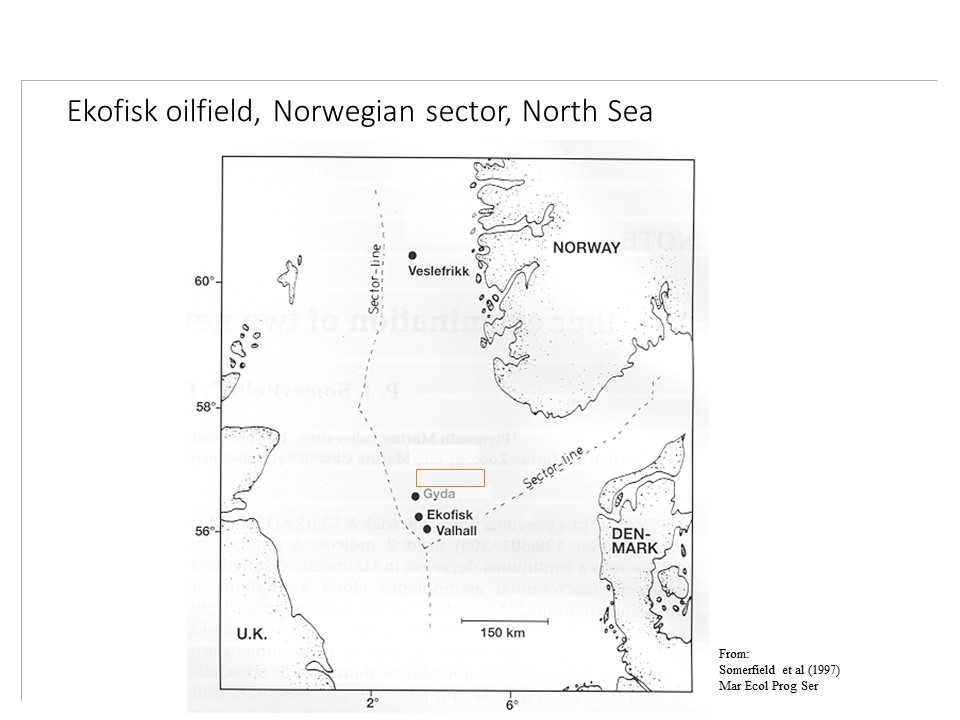
Este estudio consiste en la evaluación del macrobentos y varios contaminantes del sedimento en 39 sitios dispuestos en un diseño radial (figura 13.1 (a)) alrededor de una plataforma de perforación petrolera (figura 13.1 (b)) en el mar del Norte (figura 13.1 (c)), donde se espera que los contaminantes asociados a la actividad petrolera afecten la estructura del ecosistema. La disposición de los sitios es circular, alejándose cada ciertos kilómetros del centro de perforación. A diferencia de la activdad 4, ahora sí consideraremos las distancias de cada sitio respecto a la plataforma. Usaremos dos métodos de ordenación: PCO y MDS para representar las matriz de la macrofauna.

Importe el archivo “macrofauna.cvs” y renómbrela datos. Identifique la información de sus columnas y filas.
Recuerde que se deben filtrar las primeras dos columnas. Llame a la nueva matriz “macrofauna”
macrofauna <- datos[,3:length(datos)]r.c y a la matriz Bray-Curtis resultante bray1.r.c <- macrofauna^(1/4)
bray1 <- vegdist(r.c)bray1 en una matriz cuadrada.bray1.m <- as.matrix(bray1)
# Luego, genere la matriz A
A<- -0.5*(bray1.m^2)
dim(A)
# Seguidamente, se debe centrar A en sus propias filas y columnas para
# generar la matriz Gower G. Trate de describir qué se está efectuando en cada paso.
nn <- dim(A)[1]
nn
ones <- matrix(1,nn)
ones
I <- diag(1,nn)
I
dim(I)
Gower <- (I-1/nn*ones %*% (t(ones))) %*% A %*% (I-1/nn*ones %*% (t(ones)))
dim(Gower)Estimada la matriz de Gower, se descomponen los autovalores para obtener los ejes o scores usando la función eigen
EG <- eigen(Gower)Para obtener la ordenación del PCoA, genere las coordenadas principales usando los autovalores con el script:
#Estimación de coordenadas
vectors <- sweep(EG$vectors, 2, sqrt(abs(EG$values)), FUN = "*")
# Identificamos a las filas de "vectors" para proyetar las etiquetas en el gráfico
row.names(vectors) <- paste(row.names(r.c))
# Generamos la ordenación usando la función ordiplot{vegan}.
# Genere el PCO proyectando las etiquetas, y luego otro PCO proyectando puntos.También podríamos generar la ordenación del PCO usando ggplot2. Esto sería como iniciar de cero, en términos de generación del gráfico, pero permitiría proyectar el PCO con las características gráficas que más nos gusten. Primero se debe generar una data.frame con los vectores con información real (excluyendo los vectores imaginarios)
scoresPCO <- as.data.frame(vectors)
# Luego le incluímos al data.frame creado el factor distancia.
# Esto será útil para proyectar un gráfico cuyos puntos estén diferenciados
# por el factor distancia.
scoresPCO$dist <- datos$`#dist`
distancia <-
as.factor(scoresPCO$dist) #con esto definimos un vector de clase "factor"
PCO.ggplot <-
ggplot(scoresPCO, aes(x = V1, y = V2, colour = distancia)) +
geom_point(size = 3) +
ylab(expression(paste("PCO2"))) +
xlab(expression(atop(paste("PCO1"))))# Proyección del PCO
PCO.ggplot #imprimir gráfico en la consolaPCO.r <- cmdscale(bray1, k = (nrow(r.c) - 1), eig = TRUE)
ordiplot(scores(PCO.r)[, c(1, 2)], type = "p", main = "PCoA con cmdscale y Vegan")
ordiplot(scores(PCO.r)[, c(1, 2)], type = "t", main = "PCoA con cmdscale y Vegan")pco del paquete ape.PCO.ape <- pcoa(bray1)biplot para tal finbiplot(
PCO.ape,
Y = r.c,
plot.axes = c(1, 2),
dir.axis1 = 1,
dir.axis2 = 1,
main = "PCO pcoa{ape} 2- Macrofauna"
)Mejoremos el PCO incluyendo solo a las 10 especies que mejor contribuyen a diferenciar los grupos en las distancias 1 y 4. Para esto usaremos la herramienta SIMPER desarrollada por Clarke (1993), original del software PRIMER, pero incluída en el paquete vegan. Esta rutina descompone las similitudes entres cada par de sitios y relativiza el peso de cada especie en contribuir a la disimilitud promedio entre dos grupos.
Apliquemos simper a la matriz “r.c” usando el factor distancia. Para poder acceder al resultado, llamaremos a este simper_1v4 y al resumen de los resultados sum1v4
simper_1v4 <- simper(r.c, distancia)
sum1v4 <- summary(simper_1v4)sum1v4$`1_4`sp <- rownames(as.data.frame(sum1v4$`1_4`[1:20, ]))
r.c.sub <- as.matrix(r.c[, sp])biplot(PCO.ape, Y=r.c[,sp],
plot.axes = c(1,2),
dir.axis1=1,
dir.axis2=1,
main="PCO pcoa{ape} 2- Macrofauna")PCO.ape$values$Relative_eig[1:2] # Autovalores del PCO1 y PCO2
PCO.ape$values$Relative_eig[1:2] * 100 # Valores convertidos %
sum(PCO.ape$values$Relative_eig[1:2] * 100)
#esta suma indica cuánta de la variación en la matriz bray1 es proyectada por los dos
#primeros ejes del PCO. ¿cree usted que es una buena ordenación?plotnMDS <- metaMDS(r.c,
distance = "bray",
k = 2,
trymax = 30)
plot(MDS, display = "sites")
text(MDS, display = "sites")
title(main = "MDS con metaMDS, Bray-Curtis macrofauna")
mtext(text = paste("stress =", round(MDS$stress, 3)), outer = FALSE)mMDS <- metaMDS(bray1, model = "linear", trymax = 200)
plot(mMDS$points)
shp <- Shepard(d = bray1, x = mMDS$points)
plot(shp)
lines(shp$x, shp$y, type = "S")# Extraer coordenadas de cada muestra
nMDS.ejes <- as.data.frame(nMDS$points)
#Agregar el factor distancia a la tabla
nMDS.ejes$distancia <- distancia
#Gráfico base
nMDS.plot <- ggplot(nMDS.ejes, aes(x = MDS1, y = MDS2, colour = distancia))+
geom_point(size = 4)
#Mejora estética del nMDS
nMDS.plot +
theme_bw()+
theme(
panel.grid.major = element_blank(),
panel.grid.minor = element_blank()
)+
theme(axis.ticks = element_blank(), axis.text = element_blank())+
ggtitle("nMDS con monoMDS, Bray-Curtis macrofauna",
subtitle = paste("stress =", round((nMDS$stress),3)))dplyr para manejar con mayor facilidad la data.frame scoresPCO. Lo primero es convertir esa data.frame a tabla con la función as.tblscoresPCO.tb <- as_tibble(scoresPCO)scoresPCO.dist <- group_by(scoresPCO.tb, dist)centroides. Luego de aplicar el script trate de identificar las dimensiones de centroides. ¿Reconoce lo que se calculó?centroides <- scoresPCO.dist %>%
summarise_all(mean) %>%
as.data.frame()
centroidesdist.cen. Proyecte esta matríz de distancias con un PCO usando cmdscaledist.cen <- vegdist(centroides[2:33], method = "euclidean")
PCO.cen <- (cmdscale(dist.cen))
ordiplot(PCO.cen)