3 Datos biológicos, ecológicos y ambientales (BEA)
3.1 Variantes de estructuras de datos BEA multivariados
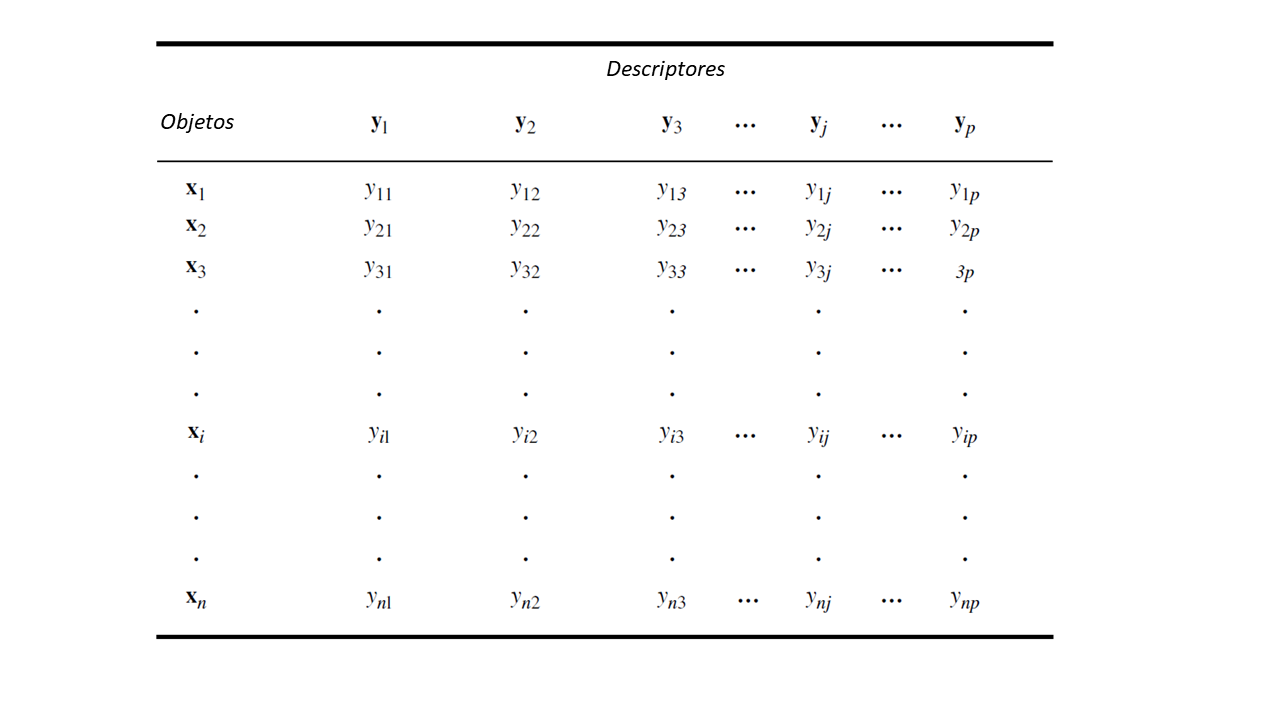
Los datos BEA de estructura multivariada suelen estar dispuestos en una matriz rectangular en el que cada fila representa una muestra y cada columna representa una variable medida en cada muestra. En terminología estadística multivariada, cada muestra recibe el nombre de objeto, y cada variable el de descriptor (sensu Legendre y Legendre (2012)). Así, una matriz puede tener N objetos y P descriptores (figura 3.1), y la multiplicación de estas define la cantidad de datos y tamaño de la matriz.
Dependiendo del tipo de estudio, las propiedades numéricas de las matrices BEA cambiarán, repercutiendo en las decisiones que debemos tomar sobre cómo abordar los datos. En ciencias biológicas, cuando el interés es comparar organismos, las matrices pueden incluir información sobre la expresión genética, fisiología, forma, conducta, entre otras P variables, medidas a un N número de organismos. En ecología, las matrices pueden comprender la presencia o abundancia de P especies en N muestras o sitios. En estudios ambientales, las matrices pueden incluir mediciones de P variables como pH, concentraciones de nutrientes, contaminantes, temperatura, etc., en un conjunto de N muestras o sitios. Para cada caso, las matrices tendrán unas propiedades matemáticas particulares que deben ser reconocidas antes de iniciar cualquier análisis formal. Las características principales de cada tipo de matriz BEA multivariados se pueden resumir de esta forma:
Datos biológicos: Comunes en estudios experimentales sobre fisiología y biología de organismos. Los objetos son individuos o muestras de tejido, sangre, etc., de individuos de una o varias especies sujetas a algún tipo de muestreo o experimento. En estos se pueden tener estimaciones de variables como peso, tamaño, concentración de alguna sustancia en sangre, expresión de genes, contenido estomacal, etc. que pueden presentar diferentes unidades y escalas. Incluso, suele haber información cualitativa como la madurez sexual del individuo (juvenil, adulto, senescente), la expresión de algún tipo de enfermedad (A, B, C o D) o alguna otra respuesta o atributo del individuo o muestra del tipo nominal. Usualmente, todas las variables biológicas fueron medidas en todas las muestras y normalmente hay más muestras que variables. Una excepción pueden ser estudios de contenido estomacal o estudios genéticos, en las que el tipo y cantidad de cada ítem alimenticio o de genes registrados en cada individuo es considerablemente más alto que el número de individuos estudiados.
Datos ecológicos: Comunes en estudios de comunidades y diversidad de especies. Los objetos son sitios o muestras recolectadas en los sitios. En estas matrices se registra la presencia de P especies, y en muchos casos alguna estimación de la abundancia de estas, bien sea como número de individuos, biomasa, volumen o cobertura. A diferencia de las matrices biológicas o ambientales, las abundancias de todas las especies deben estar medidas en la misma unidad, y en la gran mayoría de los casos hay muchas más variables que muestras (P > N). La característica más importante de este tipo de datos es que no todas las especies están registradas en todas las muestras. Esta propiedad es muy particular porque hace que las matrices estén dominadas en valores 0, lo que es equivalente a decir que la especie estuvo ausente en esa muestra. Similarmente, las varianzas de las abundancias por especie suelen aumentar con el promedio. En consecuencia, las distribuciones de frecuencia suelen ser muy sesgadas a la derecha. Además, a pesar de ser la misma unidad de abundancia para todas las especies, los rangos de variación suelen ser muy amplia y variable entre especies.
Datos ambientales: Comunes en estudios de caracterización ambiental, seguimiento ambiental y contaminación. Los objetos suelen ser muestras de agua, sedimento o aire. Se caracterizan por tener variables con diferentes unidades como temperatura, pH, humedad, nutrientes, proporciones, concentraciones de moléculas orgánicas o inorgánicas, concentración de metales, sales, entre otras. Las variables suelen tener diferentes órdenes de magnitud, algunas en decimales, otras en unidades o decenas, incluso centenas o mayor. Otra característica importante es que todas las variables fueron (o debieron ser) medidas en todas las muestras; la ausencia de una medición de una variable en alguna muestra normalmente es accidental. Usualmente hay más muestras que variables (N > P); no obstante, en estudios de ecotoxicología, donde se miden metales pesados o compuestos orgánicos con instrumentos de alta resolución, es muy probable que se tengan más variables.
Como se verá más adelante, en alguna etapa del procesamiento estadístico multivariado, se deberá aplicar algún tipo de medida de asociación que implicará operaciones aritméticas en que la unidad, escala de magnitud y forma de la distribución de frecuencia de cada variable repercutirá sustancialmente en el análisis multivariado. Por esta razón, en la gran mayoría de los casos, se deben aplicar transformaciones matemáticas y estadísticas a los datos BEA antes de iniciar el análisis.
3.2 Transformaciones matemáticas a datos BEA
Las transformaciones matemáticas a los datos BEA previas a cualquier análisis estadístico multivariado son siempre necesarias. Las razones son varias, pero la más importante es que tenemos interés en que todas las variables aporten al patrón. No aplicar alguna transformación implicará que alguna o algunas variables contribuyan mucho más que otras al resultado, y la ventaja que da la aproximación multivariada se perderá.
Los procedimientos para aplicar transformaciones a los datos previo a efectuar un análisis multivariado son muy dependientes del tipo de datos y de los objetivos del estudio. Acá nos centraremos en plantear las más importantes con base en las respuestas a las siguientes preguntas:
- ¿Las unidades de muestreo tienen el mismo tamaño?
Normalmente los estudios son diseñados con unidades de muestreo que son de tamaño estándar: cuadrantes de 1m2 , transectos de 100 m lineales, botellas de agua de 1 litro, etc. Sin embargo, esto no siempre es factible y las diferencias en el tamaño de la unidad de muestreo pueden incidir sustancialmente en el resultado. Por ejemplo, en el caso de una matriz biológica en que interesa comparar contenidos estomacales, difícilmente los individuos muestreados tendrán exactamente el mismo tamaño. Incluso, en el caso de disponer individuos del mismo tamaño, no tendrán los estómagos igualmente repletos para el momento en que son muestreados. Similarmente, hay otras situaciones en la que intentamos tener muestras estandarizadas, pero por asuntos logísticos, o incluso por la efectividad del instrumento de muestreo, no es posible tener muestras con magnitudes de información comparable. Un ejemplo en estudios ambientales pueden ser el tamaño de la muestra de sedimentos obtenidas con núcleos o las dragas: aunque el artefacto sea al mismo en todos los sitios, no siempre podrá cargar la misma cantidad de sedimento. Ante este escenario, en el de los estómagos, o cualquier otro en que las magnitudes de la información obtenida dependan de asuntos fortuitos, será necesario aplicar algún tipo de corrección. Uno de los métodos más comunes es relativizar los valores de expresión de cada variable al total de información de la muestra; es decir, estandarizar (en proporción o porcentaje) la contribución relativa de cada variable respecto al total de variables contabilizadas en la muestra. Esto se logra con la simple ecuación:
\(p_{ij} = \frac{n_{i}}{N_{j}}\)
Donde p es la proporción estandarizada de la variable i en la muestra j; n es la magnitud absoluta de la i-ésima variable y N es el número absoluto total de todas las variables en la j-ésima muestra. Noten que esto solo aplica a variables que se miden en la misma unidad y que son partes de un todo; como la estructura de especies en una comunidad (se cuentan individuos de cada especie), composición granulométrica del sedimento (cantidades de cada fracción de grano), composición de hidrocarburos en agua o sedimento (cantidades de cada fracción de compuestos aromáticos), composición de células en sangre (cantidades de cada tipo de célula por micolitro). Con esta estrategia interesa evaluar las diferencias en las fracciones relativas de cada variable entre cada par de muestras, más que los patrones de magnitud absolutos. Por ejemplo, en tabla 3.1 se pueden apreciar las abundancias absolutas de cinco especies de poliquetos en cinco muestras de sedimento tomadas con la misma draga, pero la eficiencia de mordida de la draga no fue constante; en efecto, la draga fue 100 % eficiente en la muestra 2 y 3, pero poco eficiente en las muestras 1, 4 y 5; por lo que la cantidad de sedimento muestreado y por ende de individuos recolectados se verá afectada. Este problema es muy común en estudio de bentos, pero no representa un problema mayor si las muestras se estandarizan. Noten en la tabla 3.2 cómo la transformación a la suma de organismos de la muestra permite obtener abundancias relativas y ahora comparables entre muestras.
Código
# Generar datos de abundancia para cada especie
Sp1 <- c(0,0,1,3,2)
Sp2 <- c(11,16,79,18,9)
Sp3 <- c(0,0,0,23,0)
Sp4 <- c(18,33,165,0,21)
Sp5 <- c(40,88,320,33,57)
# Crear un data frame con los datos
datos <- data.frame(Sp1, Sp2, Sp3, Sp4, Sp5)
rownames(datos) <- c("Muestra_1", "Muestra_2", "Muestra_3", "Muestra_4", "Muestra_5")
# Crear la tabla con knitr
library(knitr)
library(dplyr)
kable(datos|>
mutate(Total = Sp1+Sp2+Sp3+Sp4+Sp5))
library(vegan)
datos_s <- round(100*decostand(datos, method = "total"),0)
kable(datos_s|>
mutate(Total = Sp1+Sp2+Sp3+Sp4+Sp5))| Sp1 | Sp2 | Sp3 | Sp4 | Sp5 | Total | |
|---|---|---|---|---|---|---|
| Muestra_1 | 0 | 11 | 0 | 18 | 40 | 69 |
| Muestra_2 | 0 | 16 | 0 | 33 | 88 | 137 |
| Muestra_3 | 1 | 79 | 0 | 165 | 320 | 565 |
| Muestra_4 | 3 | 18 | 23 | 0 | 33 | 77 |
| Muestra_5 | 2 | 9 | 0 | 21 | 57 | 89 |
| Sp1 | Sp2 | Sp3 | Sp4 | Sp5 | Total | |
|---|---|---|---|---|---|---|
| Muestra_1 | 0 | 16 | 0 | 26 | 58 | 100 |
| Muestra_2 | 0 | 12 | 0 | 24 | 64 | 100 |
| Muestra_3 | 0 | 14 | 0 | 29 | 57 | 100 |
| Muestra_4 | 4 | 23 | 30 | 0 | 43 | 100 |
| Muestra_5 | 2 | 10 | 0 | 24 | 64 | 100 |
Alternativamente, puede interesar comparar las fracciones relativas de cada variable respecto al total de cada variable en todas las muestras, o respecto al máximo de cada variable en todas las muestras, o respecto a a algún valor de referencia. Otra aproximación puede ser interpolar o extrapolar por el tamaño de la unidad de muestreo a algún tamaño estándar.
- ¿Existen variables con valores extremos en sus distribuciones?
Lo más probable es que sí: habrán valores extremos y distribuciones muy sesgadas a la derecha. Aunque esto suele ser visto como un problema en análisis estadísticos convencionales, esta condición es común en datos BEA multivariados. En estadística paramétrica convencional, es requerido aplicar alguna transformación a los datos para poder satisfacer las necesidades de distribución de residuales en la mayoría de los procedimientos estadísticos convencionales (Quinn y Keough (2002)). No obstante, en estadística multivariada basada en distancias no es necesario forzar el los datos o los residuales de un modelo a alguna distribución convencional (e.g. Normal) (Clarke 1993). Sin embargo, es deseable que las variables con valores extremos no dominen los cálculos, y por ello deben explorarse los datos en sus magnitudes originales para decidir el tipo de transformación.
Las transformaciones de potencia ( y* = y𝛌 ) son estrategias valiosas para reducir la asimetría de los datos. Al variar el valor de 𝛌, se pueden aplicar ajustes que van desde sutiles hasta extremadamente pronunciados. No es necesario identificar con precisión el valor de 𝛌 para cada conjunto de datos; más bien, se busca una transformación adecuada para remover parte del sesgo y lograr que todas las variables contribuyan al patrón multivariado. Las opciones comunes incluyen no realizar transformación alguna (𝛌 = 1), o aplicar transformaciones como la raíz cuadrada (𝛌 = 0.5), la raíz cuarta (𝛌 = 0.25), la transformación logarítmica de 1 + y (𝛌 ⟶ 0), o potencia de 0 (𝛌 = 0), dependiendo de las características de los datos y los objetivos del análisis.
En el caso de datos ecológicos, el propósito particular de las transformaciones de potencia es regular la contribución de las especies muy abundantes y dar mayor peso a las especies raras. Por esta misma razon, la transformación se aplica sobre toda la matriz. Básicamente, las transformaciones de potencia proporcionan un continuo de efecto desde ( 𝛌 = 1 ) (sin transformación), donde solo las especies comunes contribuyen a la similitud, pasando por ( 𝛌 = 0.5 ) (raíz cuadrada), que permite que las especies de abundancia intermedia jueguen un papel, hasta (𝛌 = 0.25 ) (raíz cuarta), que también considera en cierta medida a las especies más raras. Como se mencionó anteriormente, (𝛌 ⟶ 0) puede considerarse equivalente a la transformación logarítmica natural ( loge(y) ), y esta última sería, por lo tanto, más severa que la transformación de raíz cuarta. En el caso de la transformación logarítmica, la práctica común es usar el loge(1+y)) en lugar del loge(y), ya que el loge(1+y) siempre es positivo para y positivo mientras que el loge(1+y) = 0 para y = 0.
Por otra parte, en el análisis de datos ambientales, es fundamental identificar selectivamente las asimetrías en variables individuales, en vez de aplicar una transformación uniforme a todas como en el caso de datos ecológicos. El enfoque principal debe ser la detección y corrección de distribuciones sesgadas en las muestras, para prevenir que los valores extremadamente altos de algunas variables sesguen los resultados del análisis.
- ¿Tienen las variables la misma escala e unidad?
Los datos ecológicos suelen estar expresados en la misma unidad, bien por que se cuentan los individuos de cada especie o porque se estima su abundancia como biomasa o cobertura, por lo que más allá de aplicar alguna transformación de potencia para balancear la importancia de las especies abundantes y raras, no se requiere ninguna otra transformación adicional. No obstante, para datos biológicos o ambientales, es importante identificar si las variables tienen la misma escala y unidad de medición, ya que las diferencias en estas propiedades pueden distorsionar los resultados de los análisis y hacer que las comparaciones entre variables sean difíciles o incluso incorrectas. Cuando las variables tienen diferentes unidades de medición y escalas numéricas, las que tienen valores más grandes pueden dominar los resultados y sesgar las conclusiones del análisis. Para convertir todas las variables a la misma escala y remover la unidad de medición, se debe aplicar una normalización a los datos.
La normalización consiste en restar el promedio de la variable a cada medición y luego dividir por la desviación estándar. Esto transforma los datos a equivalentes Z de una distribución normal estandarizada para que tengan una media de cero y una desviación estándar de uno, lo que hace que todas las variables estén en la misma escala. La aproximación sigue la siguiente ecuación:
\(z_{ij} = \frac{n_{i}-\bar{x_{j}}}{s_{j}}\)
Esta operación, aunque provenga como cálculo de la distribución normal estándar no modifica la forma de la distribución de la variable, por lo que no convierte a las variables en datos con distribución normal; solo se remueve el efecto de la unidad y la escala para referirlos a unidades estándares, lo cual permite la comparación entre todas las variables.
También conocida como distribución gaussiana, es un tipo de distribución para una variable aleatoria continua que es simétrica alrededor de su media, mostrando que los datos cerca del promedio son más frecuentes en ocurrencia. Las principales propiedades de la distribución normal relacionadas con la desviación estándar son:
Aproximadamente el 68% de los datos caen dentro de 1 desviación estándar de la media (μ ± σ).
Alrededor del 95% de los datos están dentro de 2 desviaciones estándar (μ ± 2σ).
Cerca del 99.7% de los datos se encuentran dentro de 3 desviaciones estándar (μ ± 3σ).
Esto significa que cuanto más lejos esté un punto de datos de la media, menos probable es su ocurrencia. La distribución normal es fundamental en estadística debido a muchas técnicas estadísticas asumen que los datos (o al menos los residuos de los modelos) siguen una distribución normal.
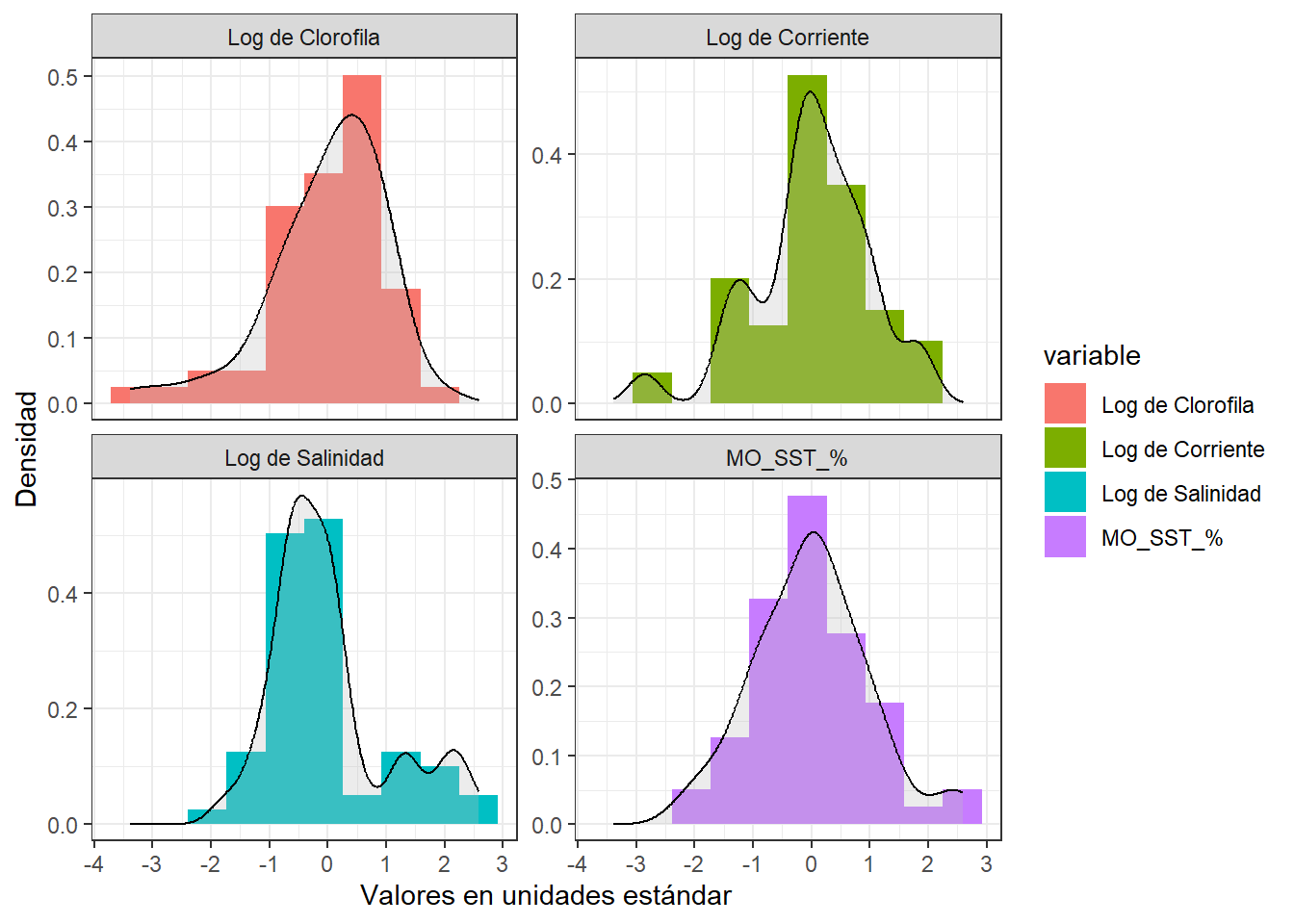
Veamos este efecto en las siguientes cuatro variables que provienen del juego de datos de Guerra-Castro et al. (2021). Los datos consiste en promedios de 16 variables fisicoquímicas del agua a lo largo de 12 localidades de una laguna costera, evaluado en cinco momentos durante 2009 y 2010. Para efectos demostrativos, solo representaremos la distribución a cuatro variables: clorofila (mg/m3), velocidad de corriente (cm/min), porcentaje de materia orgánica en sólidos suspendidos, y salinidad. En la figura 3.2 se pueden apreciar las distribuciones de frecuencia y funciones de densidad de cada variable; noten cómo difieren las escalas en cada variable, particularmente el orden de magnitud de las unidades en que se midió la velocidad de corriente. Si las diferencias en las escalas no se remueven, difícilmente las otras tres variables, en especial la clorofila, podrán aportar a algún análisis multivariado. Noten también la forma de la distribución de cada variable, que exceptuando la materia orgánica, la mayoría tienen distribución sesgada a la derecha. Al aplicar la normalización, podrá notar en la figura 3.3 que ahora todas las variables están centradas en 0, la escala es la misma en las cuatro variables, pero se mantiene la distribución original de cada variable.
Código
library(readxl)
library(dplyr)
library(tidyr)
library(ggplot2)
library(vegan)
datos_amb <- read_excel("datos/datos_ambientales_PNLR.xlsx")
datos_amb|>
select(`Corriente (cm/min)`, Salinidad, `Clorofila a mg/m3`, `MO_SST_%`)|>
pivot_longer(cols = 1:4, names_to = "variable", values_to = "valores")|>
ggplot(aes(x = valores, y = after_stat(density)))+
facet_wrap(~variable, scales = "free")+
geom_histogram(aes(fill = variable), bins = 10)+
geom_density(fill = "grey", alpha = .3)+
xlab("Valores en unidades originales")+
ylab("Densidad")+
theme_bw()
#|fig-colwidths: [60,40]
#|message: false
#|warning: false
datos_amb|>
select(`Corriente (cm/min)`, Salinidad, `Clorofila a mg/m3`, `MO_SST_%`)|>
decostand(, method = "standardize")|>
pivot_longer(cols = 1:4, names_to = "variable", values_to = "valores")|>
ggplot(aes(x = valores, y = after_stat(density)))+
facet_wrap(~variable)+
geom_histogram(aes(fill = variable), bins = 10)+
geom_density(fill = "grey", alpha = .3)+
scale_x_continuous(breaks = seq(-4,4,1))+
xlab("Valores en unidades estándar")+
ylab("Densidad")+
theme_bw()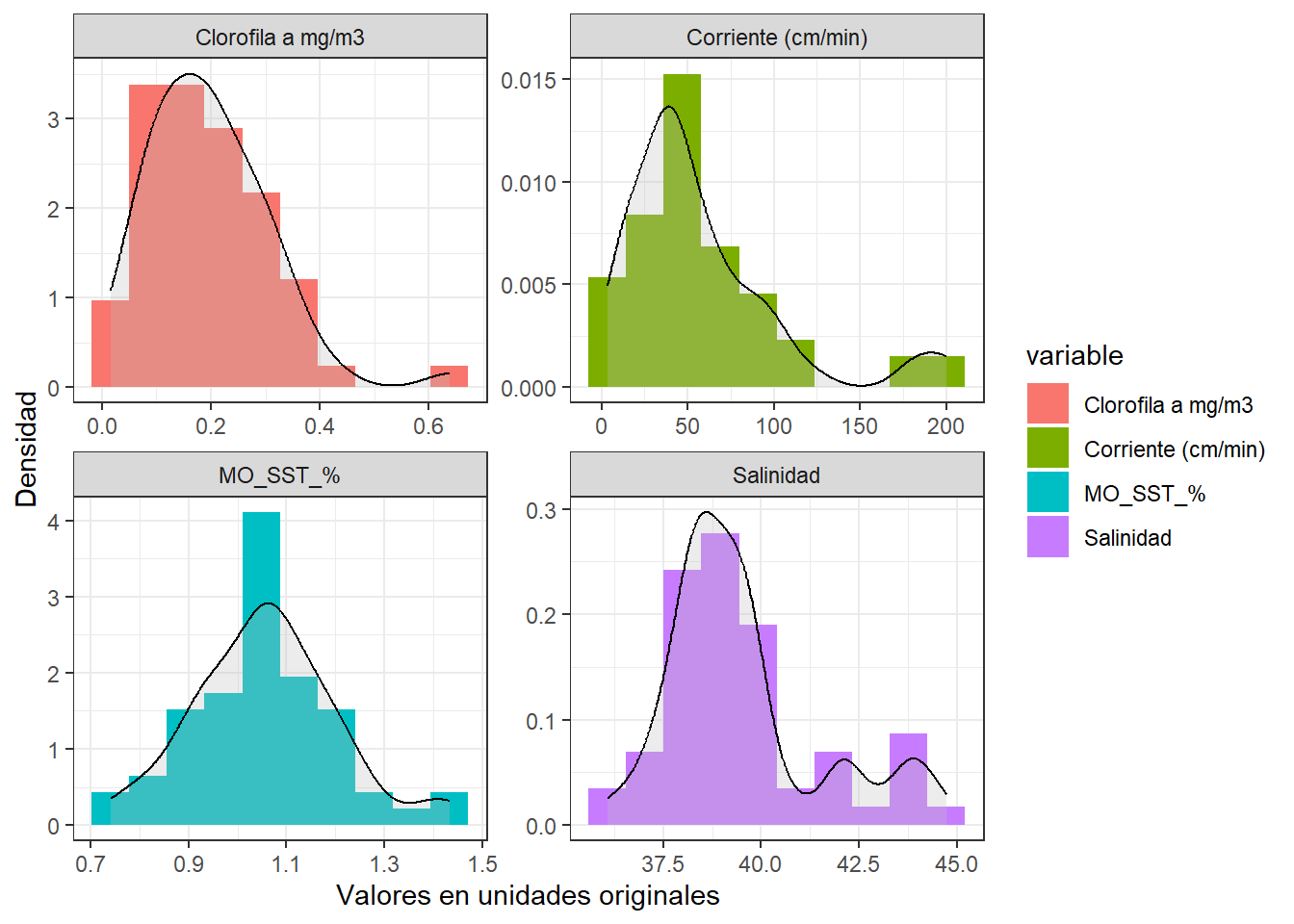
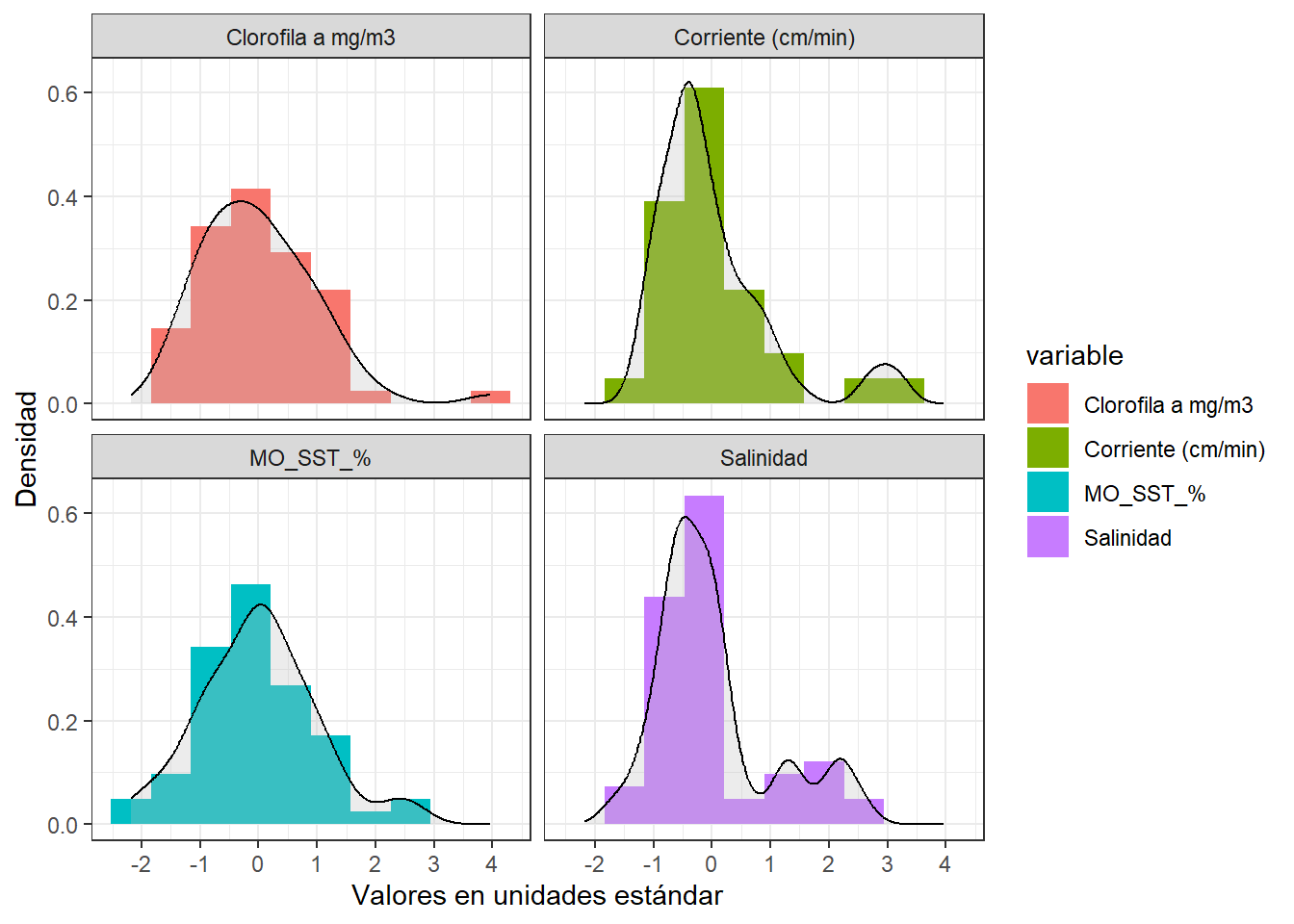
Código
#|fig-colwidths: [60,40]
#|message: false
#|warning: false
datos_amb|>
select(`Corriente (cm/min)`, Salinidad, `Clorofila a mg/m3`, `MO_SST_%`)|>
mutate(`Log de Corriente` = log(1+`Corriente (cm/min)`),
`Log de Salinidad` = log(Salinidad),
`Log de Clorofila` = log(`Clorofila a mg/m3`))|>
decostand(, method = "standardize")|>
pivot_longer(cols = 4:7, names_to = "variable", values_to = "valores")|>
ggplot(aes(x = valores, y = after_stat(density)))+
facet_wrap(~variable, scales = "free_y")+
geom_histogram(aes(fill = variable), bins = 10)+
geom_density(fill = "grey", alpha = .3)+
scale_x_continuous(breaks = seq(-4,4,1))+
xlab("Valores en unidades estándar")+
ylab("Densidad")+
theme_bw()Ahora bien, es importante enfatizar que antes de la normalización se debió haber aplicado alguna transformación de potencia a la clorofila, velocidad de corriente y salinidad para reducir la asimetría. Solo para efectos demostrativos no se aplicaron transformaciones individuales, pero sí debe hacerse. Este paso es muy importante en un análisis real ya que se debe evitar que valores extremos dominen el resultado. En la figura 3.4 se demuestra cómo la transformación logarítmica a los datos de corriente, salinidad y clorofila, y luego la normalización de las cuatro variables, permite tener variables con la misma unidad y patron de distribución estadístico. Como se puede apreciar, las transformaciones matamática a datos BEA son fundamentales antes de proceder con cualquier análisis multivariado. No hacerlo implicará errores de procedimiento que difícilmente serán advertidos, pero que sí repercutirán notablemente en los patrones.