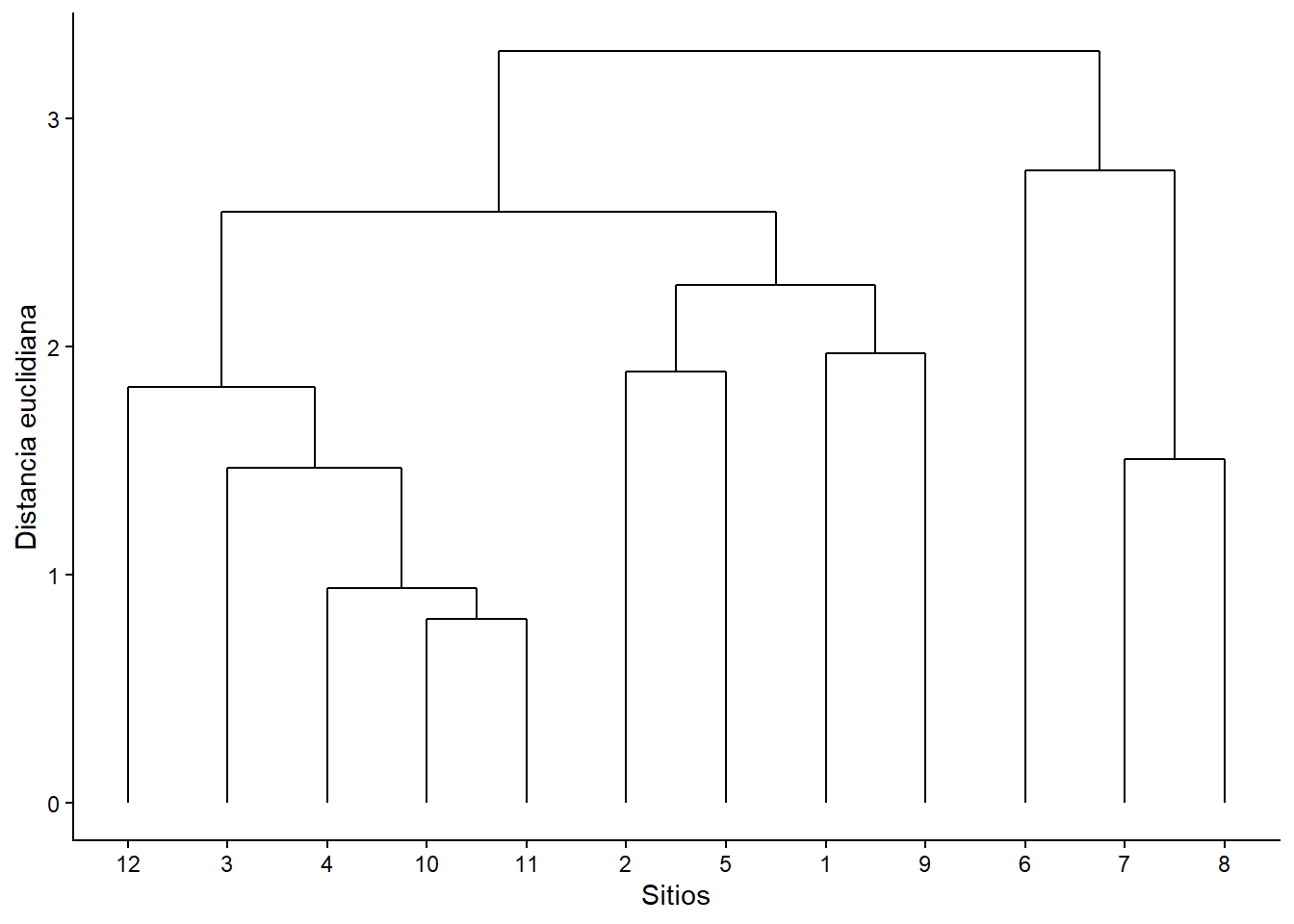En el Capítulo 5 aprendimos a estimar cuán similares, o diferentes, son dos entidades naturalmente reconocibles. Por ejemplo, es posible comparar la composición de peces en dos arrecifes coralinos, comparar las características del agua de dos lagunas o estimar cuán diferentes son las formas de dos aves de diferente especies, usando algún coeficiente de similitud o distancia. Comprender el grado de similitud entre estas dos entidades puede resultar intuitivo si se comprende cómo funciona el coeficiente elegido. Sin embargo, al comparar múltiples entidades u objetos, identificar patrones de similitud se vuelve más complejo ya que son múltiples las comparaciones que debemos analizar. Por esta razón, es necesario utilizar aproximaciones que permitan establecer relaciones de similitud de manera rápida e intuitiva. Los métodos de clasificación o análisis de conglomerados son una de las herramientas disponibles en el análisis multivariado que facilitan esta comparación.
El objetivo fundamental del análisis de clasificación es identificar agrupamientos naturales de muestras, de tal manera que los objetos dentro de un grupo sean, por lo general, más similares entre sí que con respecto a los objetos de otros grupos. En el contexto de las ciencias ambientales, donde el entorno se percibe a menudo como un continuo de variación, la clasificación requiere un grado de abstracción para reconocer subconjuntos discontinuos. Esta estructura impuesta sobre los datos permite obtener una visión simplificada y estructurada, lo que frecuentemente se denomina tipología (un sistema de tipos) para describir la estructura de dicho continuo.
Para complementar los principios básicos de esta herramienta, es necesario considerar los siguientes puntos extraídos de la literatura técnica:
Naturaleza heurística: A diferencia de otros métodos multivariados, el agrupamiento es primordialmente un procedimiento heurístico y no una prueba estadística típica; no busca probar una hipótesis, sino ayudar a resaltar características estructurales ocultas en los datos. Por ello, es el investigador quien debe decidir si las estructuras resultantes son ecológicamente interpretables y valiosas.
Importancia de las decisiones metodológicas: El resultado de una clasificación depende fuertemente de dos decisiones procedimentales: del coeficiente de asociación (similitud o distancia) y del método de agrupamiento seleccionado. El primero se puede decidir fácilmente con base en la pregunta de investigación y las propiedades naturales de los datos, como ya se vió en el Capítulo 5 . No obstante, decidir sobre el método de agrupamiento es más complejo por la alta carga de arbitrariedad de cada aproximación. Por lo tanto, decidir qué método de clasificación conviene no suele ser intuitivo.
Clasificación frente a Ordenación: Mientras que el análisis de conglomerados intenta agrupar muestras en grupos discretos, el análisis de ordenación busca mostrar sus interrelaciones en una escala continua. En situaciones de gradientes ambientales fuertes, la clasificación puede imponer divisiones arbitrarias en lo que es esencialmente un cambio gradual, por lo que ambos métodos suelen utilizarse de forma complementaria para fortalecer las conclusiones. Los métdos de ordenación se describirán en los próximos capítulos.
Particiones “duras” y descriptores: La mayoría de los métodos tradicionales generan una partición dura (o crisp), donde cada muestra pertenece a uno y solo a uno de los subconjuntos. Esto hace que el método sea bastante radical respecto a las interrelaciones de las muestras, por lo que su uso en contextos de gradiente ambiental puede no ser adecuado.
Ya hemos señalado que los métodos de clasificación tienen como objetivo agrupar muestras en conjuntos. En ciencias ambientales, este propósito no siempre es el principal; a menudo, se prefiere tratar las muestras como un continuo de variación. Es más común encontrar preguntas de investigación con grupos definidos previamente, en que el objetivo es demostrar la existencia de esos grupos, típicamente comparar muestras que provinene de lugares (o momentos) diferentes, e interesa detectar diferencias entre esos lugares o momentos. Sin embargo, en algunas situaciones es necesario identificar grupos que no son fácilmente reconocibles. Existen muchas técnicas de clasificación, generalmente divididas en: métodos jerárquicos, divisivos, agrupamiento o k-means, análisis discriminantes, entre otros. En este capítulo nos centraremos en los métodos de clasificación jerárquicos, ya que son ampliamente utilizados en ciencias ambientales.
6.2 Métodos jerárquico
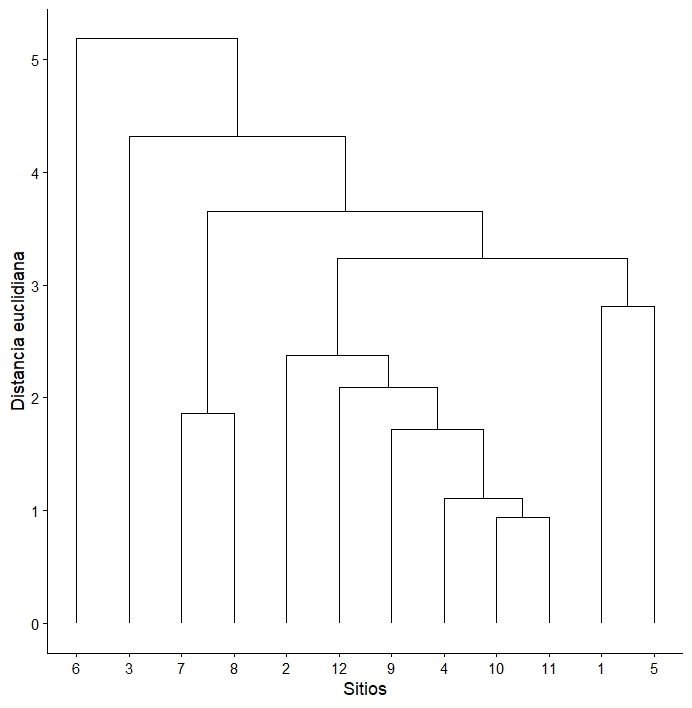
El agrupamiento jerárquico de muestras es uno de los métodos más utilizados en ciencias ambientales. El propósito de este método es clasificar los pares de muestras en conjuntos que presenten el mayor grado de similitud. Los conjuntos, a su vez, pueden ser clasificados en otros conjuntos que también presentan alta similitud. Este enfoque permite identificar niveles de agrupación basados en la importancia relativa de las similitudes, facilitando la comprensión de los patrones de asociación entre las muestras. Los métodos jerárquicos se destacan por la capacidad de representar matrices de distancias o similitud en un tipo de gráfico llamado dendrograma (figura 6.1), permitiendo identificar patrones complejos de relación entre las muestras sin necesidad de analizar cada valor de similitud individualmente. En esencia, las muestras más similares se fusionan inicialmente en grupos, y el proceso iterativo continúa ascendentemente hasta incluir todos los conjuntos en una estructura jerárquica, siempre binaria.
Fig. 6.1: Representación gráfica de un dendograma de una matriz de distancias euclidianas
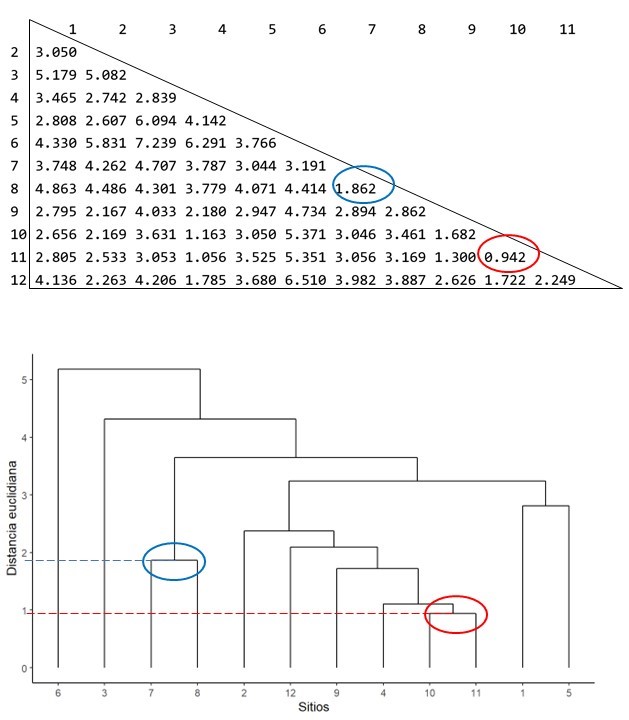
Fig. 6.2: Dendograma de la matriz de distancias euclidianas
El proceso de formación de grupos ocurre mediante la vinculación entre el par de muestras con mayor similitud, que en una primera instancia formarán un grupo compuesto por dos muestras, y que luego deberán ser asociadas como unidad a otra muestra u otro grupo que contiene otras dos muestras. Este procedimiento de fusión de grupos o incorporación de muestras a otro grupo se conoce como vinculación. Este proceso inicia identificando el par de muestras con mayor similitud (o menor disimilitud o distancia) en toda la matriz. Este primer par de muestras conforman el primer conjunto, o grupo, de todo el análisis. Por ejemplo, fíjese en la matriz de distancias euclidianas de la figura 6.2, en ella podrá identificar que la menor distancia ocurre entre las muestras 11 y 10 (i.e. 0.94). Este sería el primer grupo en el análisis. El segundo grupo compuesto por solo dos muestras lo conforman las muestras 7 y 8, con una distancia de 1.862; noten que no hay un valor de distancia mas pequeño de esas dos muestras con otras.
Seguidamente, se debe reconstruir la matriz de distancias, pero ahora con una única entrada que represente al conjunto formado por 11 y 10. El valor de distancia de este nuevo conjunto respecto al resto de las muestras dependerá del tipo de vinculación seleccionado: simple, completo o promedio. Es importante señalar que el método de vinculación elegido se aplica desde el inicio y se mantiene constante durante todo el análisis; no es posible combinar diferentes tipos de vinculación dentro de una misma clasificación jerárquica.
El método de vinculación simple, también conocido como método del vecino más cercano (nearest neighbor method), consiste en asignar a un grupo el objeto (o grupo) externo que presente la mayor similitud, o equivalentemente la menor distancia, con cualquiera de los elementos que lo conforman. Por ejemplo, en el caso ilustrado en figura 6.2, el grupo 10–11 tendrá como distancia hacia cada una de las demás muestras el menor valor entre las distancias de 10 y 11 hacia dichas muestras. Una vez estimadas todas las distancias del grupo 10–11, se identifica el siguiente objeto que se integrará al grupo. En este caso, la distancia más baja entre 10–11 y el resto de las muestras corresponde a la relación entre 11 y 4, con un valor de 1.056, ya que la distancia entre 10 y 4 es ligeramente mayor (1.163). Por lo tanto, la nueva matriz de distancias registrará el valor 1.056 para la relación entre el grupo 10–11 y la muestra 4. Por otra parte, en el método de vinculación completo, el procedimiento es opuesto al anterior: la distancia entre un grupo y un objeto externo se define como la mayor de las distancias entre los elementos del grupo y dicho objeto.
6.3 Vinculación promedio
El método de vinculación promedio utiliza el promedio de las distancias entre los elementos del grupo y cada objeto externo para determinar la magnitud de la relación entre ellos. Estas diferencias resultantes en la forma de calcular la distancia del nuevo grupo pueden observarse claramente en las matrices presentadas en la tabla 6.1.
Tabla 6.1: Matrices de distancia construidas luego del primer agrupamiento, usando alguno de los tres métodos de vinculación: simple, completo o promedio
(a) Simple
1
2
3
4
5
6
7
8
9
11-10
12
1
2
3.05
3
5.18
5.08
4
3.46
2.74
2.84
5
2.81
2.61
6.09
4.14
6
4.33
5.83
7.24
6.29
3.77
7
3.75
4.26
4.71
3.79
3.04
3.19
8
4.86
4.49
4.3
3.78
4.07
4.41
1.86
9
2.8
2.17
4.03
2.18
2.95
4.73
2.89
2.86
11-10
2.66
2.17
3.05
1.06
3.05
5.35
3.05
3.17
1.3
12
4.14
2.26
4.21
1.78
3.68
6.51
3.98
3.89
2.63
1.72
(b) Completa
1
2
3
4
5
6
7
8
9
11-10
12
1
2
3.05
3
5.18
5.08
4
3.46
2.74
2.84
5
2.81
2.61
6.09
4.14
6
4.33
5.83
7.24
6.29
3.77
7
3.75
4.26
4.71
3.79
3.04
3.19
8
4.86
4.49
4.3
3.78
4.07
4.41
1.86
9
2.8
2.17
4.03
2.18
2.95
4.73
2.89
2.86
11-10
2.8
2.53
3.63
1.16
3.52
5.37
3.06
3.46
1.68
12
4.14
2.26
4.21
1.78
3.68
6.51
3.98
3.89
2.63
2.25
(c) Promedio
1
2
3
4
5
6
7
8
9
11-10
12
1
2
3.05
3
5.18
5.08
4
3.46
2.74
2.84
5
2.81
2.61
6.09
4.14
6
4.33
5.83
7.24
6.29
3.77
7
3.75
4.26
4.71
3.79
3.04
3.19
8
4.86
4.49
4.3
3.78
4.07
4.41
1.86
9
2.8
2.17
4.03
2.18
2.95
4.73
2.89
2.86
11-10
2.73
2.35
3.34
1.11
3.29
5.36
3.05
3.31
1.49
12
4.14
2.26
4.21
1.78
3.68
6.51
3.98
3.89
2.63
1.99
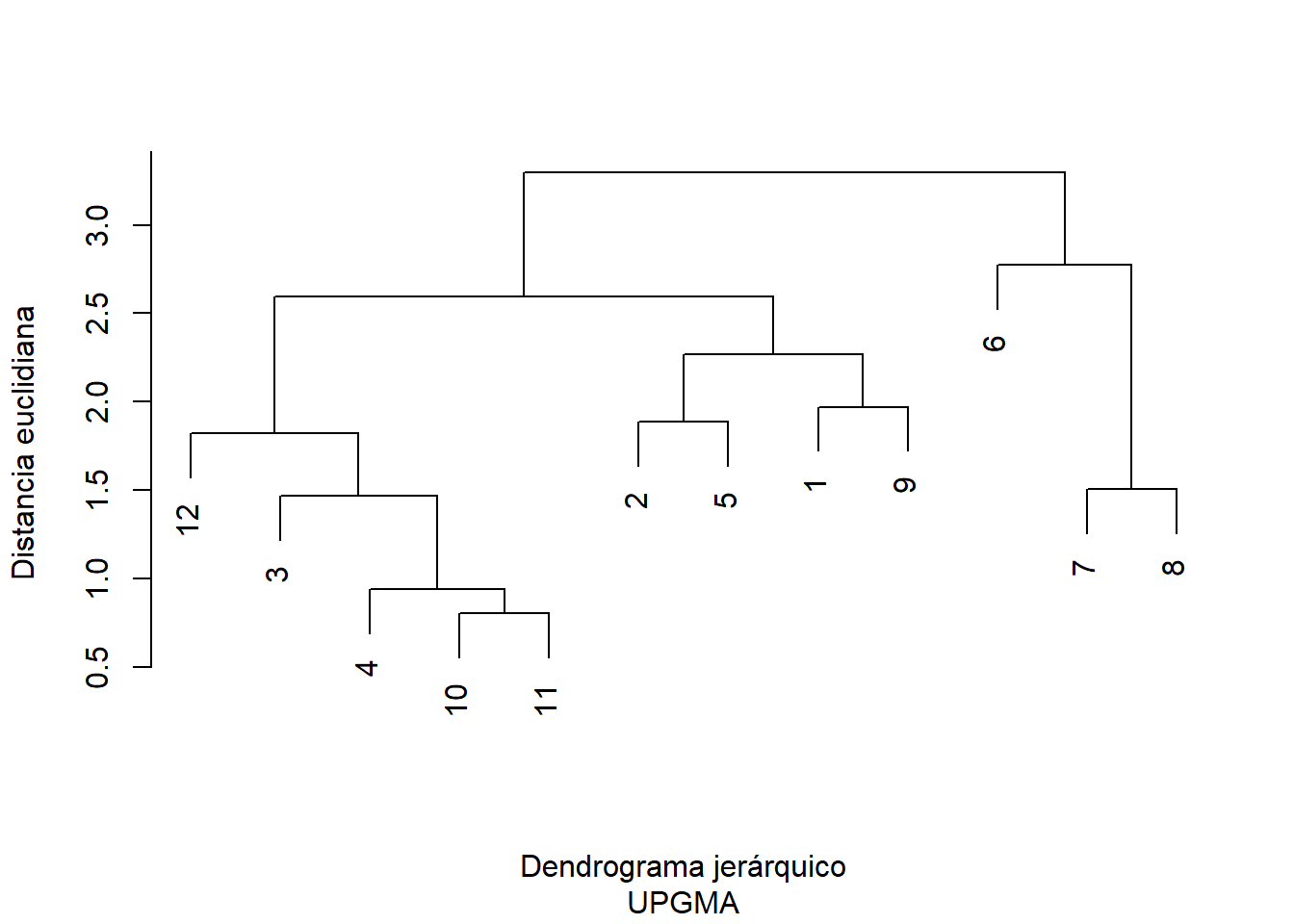
Además de estos tipos de vinculación, son varias las formas de aplicar el método de vinculación promedio. En estudios ambientales y ecológicos, destaca el UPGMA (Unweighted Pair-Group Method using Arithmetic averages). En este, un objeto se une a un grupo basándose en el promedio simple de las distancias entre dicho objeto y todos los miembros del grupo (tabla 6.1 (c)). Se denomina “no ponderado” porque otorga el mismo peso a cada observación original en el cálculo, bajo la premisa de que los objetos en cada grupo son una muestra representativa de la población de referencia. Al igual que los procesos ilustrados en la figura 6.1 y la figura 6.2, el UPGMA busca un equilibrio estructural, produciendo generalmente un número moderado de grupos de tamaño medio.
En contraste, el WPGMA (Weighted Pair-Group Method using Arithmetic averages), también conocido como vinculación de McQuitty, otorga pesos iguales a las dos ramas o grupos que están por fusionarse, independientemente del número de muestras que contenga cada uno. Esta estrategia “ponderada” es particularmente útil cuando los grupos identificados en el análisis tienen tamaños muy desiguales debido a un diseño de muestreo no aleatorio o sistemático; al promediar las ramas y no los objetos individuales, se evita que los grupos más grandes distorsionen la posición de los más pequeños, lo que suele generar clasificaciones con contrastes más nítidos.
6.4 Análisis de clasificación con R
La función principal para el agrupamiento jerárquico con R es hclust() del paquete stats. Este comando requiere como entrada una matriz de distancias generada previamente (por ejemplo, mediante dist() o vegan::vegdist()). Es importante enfatizar la importancia de haber aplicado pretratamientos a los datos antes de calcular la similitud/distancia según la naturaleza de los datos (BEA); de lo contrario, las variables con valores numéricos más grandes dominarán completamente la formación de los grupos. Una vez preparados los datos y estimada la matriz de distancias, hclust() permite seleccionar diversos criterios de vinculación.
Código
# librarías necesaria paralibrary(readxl) #leer datos de archivo excellibrary(dplyr) #transformar datoslibrary(tidyr) #ordenar datoslibrary(vegan) #calcular distancias y similitudes# Cargar datosdatos_amb <-read_excel("datos/datos_ambientales_PNLR.xlsx")# Transformar datos del muestreo 1 (son 5 muestreos)dat.t <- datos_amb|>filter(Muestreo ==1)|>select(`Corriente (cm/min)`, Salinidad,`Clorofila a mg/m3`,`MO_SST_%`)|>mutate(`Log de Corriente`=log(`Corriente (cm/min)`+1),`Log de Salinidad`=log(Salinidad),`Log de Clorofila`=log(`Clorofila a mg/m3`))|>select(-c(`Corriente (cm/min)`, Salinidad,`Clorofila a mg/m3`))# Normalizar datos (remover efecto de promedio y escala de variación)dat.m <-decostand(x = dat.t, method ="standardize")# Calcular distancia euclidiana a datos normalizadosdist <-vegdist(x = dat.m, method ="euclidean")# Apicar análisis de clasificación, en este casovinculación promedio sin ponderar (UPGMA)cluster <-hclust(d = dist, method ="average")# Construcción del dendrogramaplot(cluster, xlab ="Dendrograma jerárquico", sub ="UPGMA", main ="", ylab ="Distancia euclidiana")
Fig. 6.3: Dendograma de la matriz de distancias euclidianas usando funciones base hclut y plot
6.4.1 Optimización visual con dendextend
Para superar las limitaciones estéticas de la función base plot(), el paquete dendextend(Galili 2015) permite manipular objetos de clase dendrogram con mucha flexibilidad, permitiendo desde colorear nodos y etiquetas hasta colocar dos árboles frente a frente para su comparación. Una de sus mayores ventajas es la integración del operador pipe |>, que facilita un código más legible al encadenar modificaciones jerárquicas. A través de la función set(), se pueden ajustar parámetros gráficos como el tamaño (cex), ancho de línea (lwd), color (col) y tipo de línea (lty) tanto para las ramas como para las etiquetas y nodos.
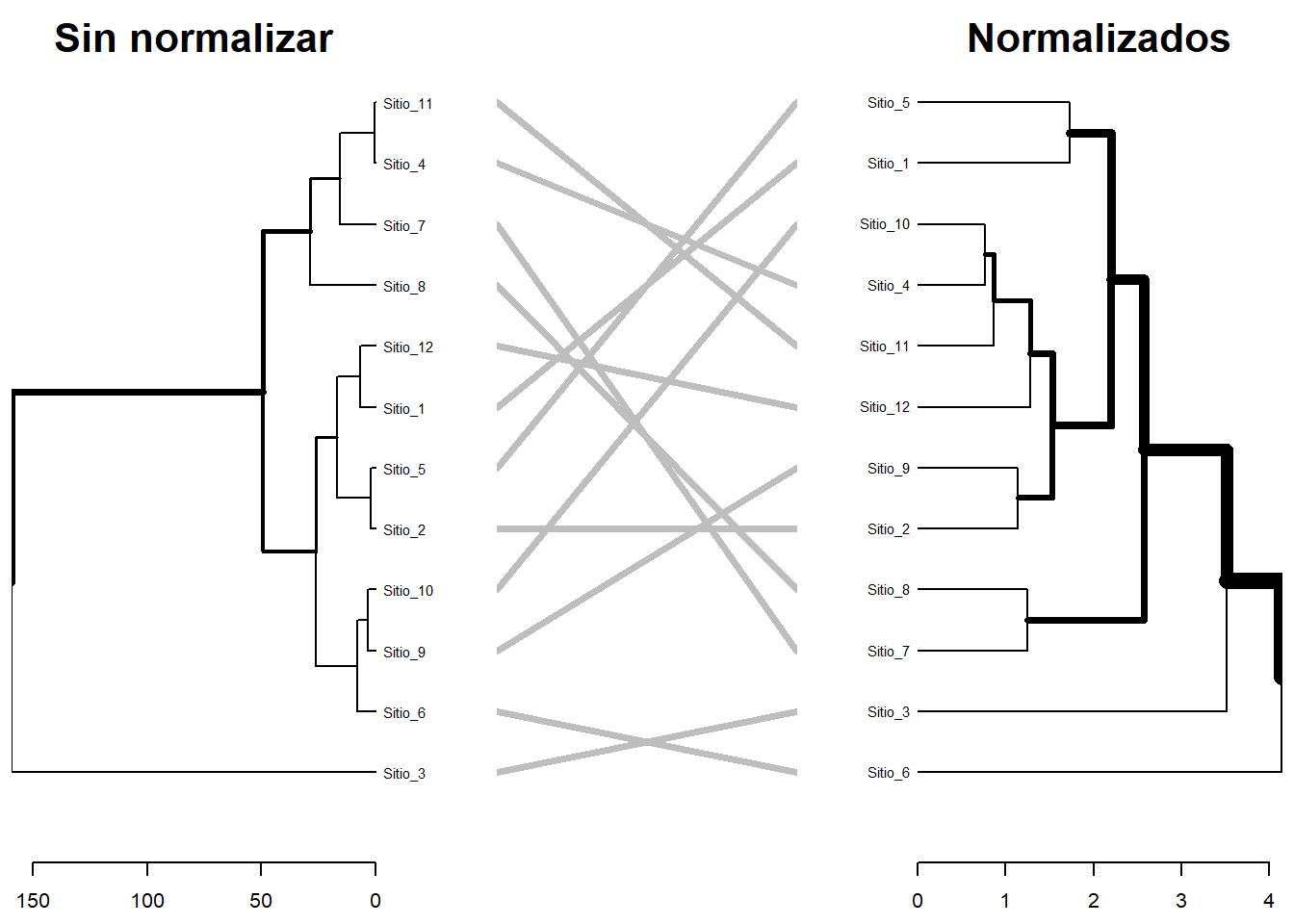
Comparación de estructuras (Tanglegram): Una de las aplicaciones más potentes es la comparación de dos dendrogramas mediante la función tanglegram(). Esta herramienta es esencial para evaluar cómo las decisiones metodológicas, como las transformaciones de datos o la normalización, impactan en la estructura final de la clasificación, permitiendo visualizar qué muestras cambian de grupo al aplicar pretratamientos. Como se observa en la comparación técnica, no es recomendable utilizar las opciones por defecto sin analizar críticamente cómo afectan la interpretación ecológica.
Código
# Paqueteslibrary(vegan)library(dendextend)library(readxl)library(dplyr)# Cargar datosdatos_amb <-read_excel("datos/datos_ambientales_PNLR.xlsx")# Datos del muestreo 1 (de 5 muestreos) sin normalizardat.st <- datos_amb|>filter(Muestreo ==1)|>select(`Corriente (cm/min)`, Salinidad,`Clorofila a mg/m3`,`MO_SST_%`)# Asignar nombres de fila explícitosrownames(dat.st) <-paste0("Sitio_", seq_len(nrow(dat.st)))# Datos del muestreo 1 (de 5 muestreos) con normalizacióndat.t <- datos_amb|>filter(Muestreo ==1)|>select(`Corriente (cm/min)`, Salinidad,`Clorofila a mg/m3`,`MO_SST_%`)|>decostand(, method ="standardize")|>as.data.frame()# Usar los mismos nombres de dat.st con rownamerownames(dat.t) <-rownames(dat.st)# Preparar dendrogramas## Para dat.st (Sin transformar/normalizar)d1 <- dat.st |>dist() |>hclust(method ="average") |>as.dendrogram() |>set("labels_cex", 0.7)## Para dat.t (Con transformaciones y normalización)d2 <- dat.t |>dist() |>hclust(method ="average") |>as.dendrogram() |>set("labels_cex", 0.7)## Crear Tanglegram para comparar dat.st vs dat.tdl <-dendlist(d1, d2)tanglegram( dl,highlight_distinct_edges =FALSE,main_left ="Sin normalizar",main_right ="Normalizados",margin_inner =5)
Fig. 6.4: Dendrograma entrelazado con tanglegram para medir el efecto de la normalización de la clasificación y proyección de relaciones en un dendograma
Como se aprecia en la figura 6.4, la aplicación de normalización en dat.t altera significativamente las distancias relativas, resultando en una estructura de agrupamiento que es más representativa de los patrones ecológicos/ambientales subyacentes al mitigar el efecto de las diferencias de escala. La capacidad de dendextend para conectar estos dos análisis visualmente permite al investigador validar la estabilidad de su clasificación recnociendo el efecto de la normalización.
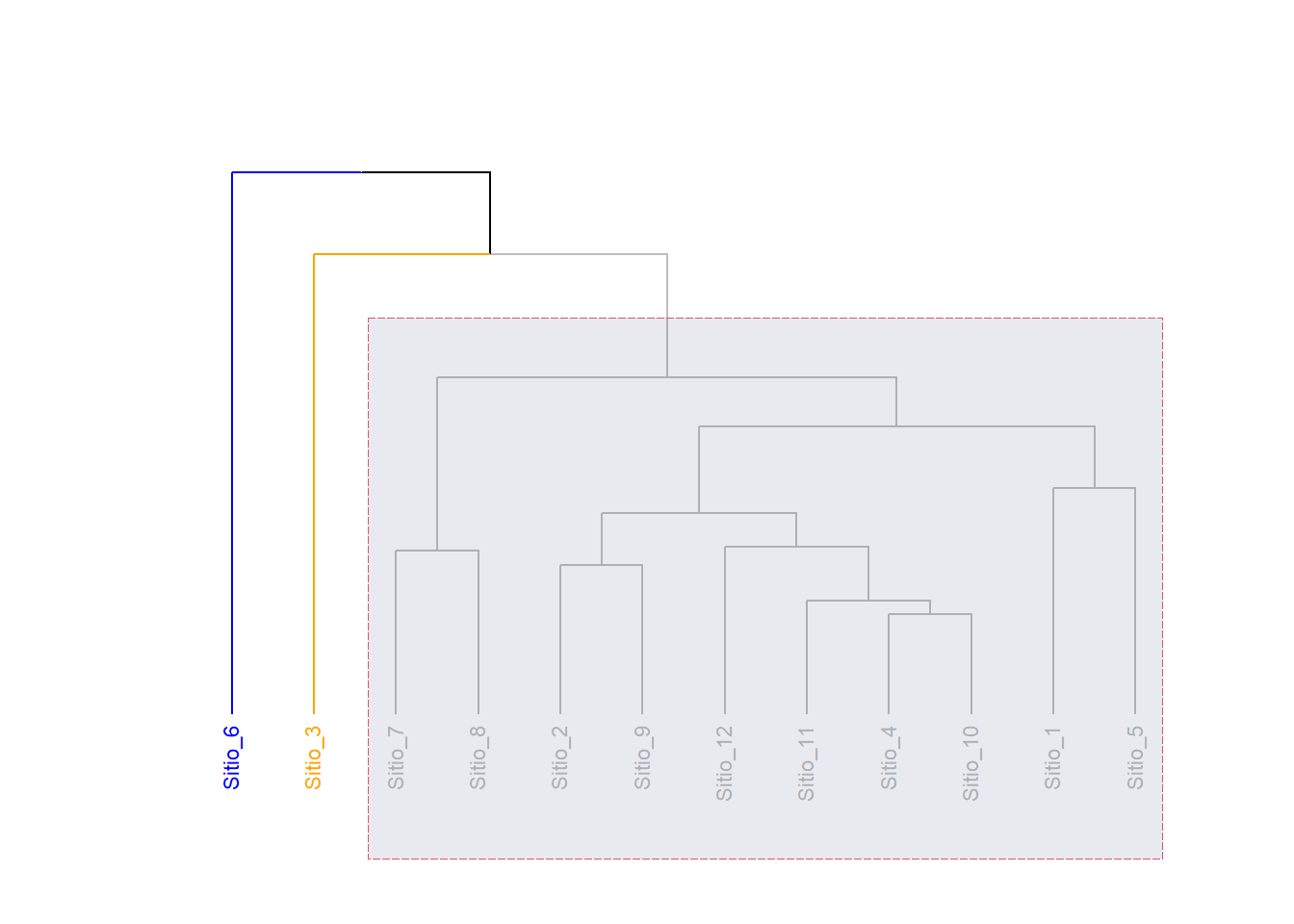
Resaltado de conglomerados: Son varias las formas de destacar grupos. La función color_branches() permite asignar colores a los grupos de forma discrecional (no es una decisión estadística). Similarmente, la función rect.dendrogram() permite resaltar uno o varios conglomerados específicos mediante recuadros sombreados, facilitando la identificación visual de subconjuntos de interés en estructuras complejas. La figura 6.5 ilustra bien el efecto de combinar ambas funciones,
Fig. 6.5: Dendrograma estilizado con tanglegram para resaltar grupos en un dendrograma con líneas coloreadas y un rectángulo
6.4.2 Integración con ggplot2
Para quienes prefieren el ecosistema de ggplot2, la integración de los análisis de clasificación con el universo tidy permite una flexibilidad total en la personalización estética y estructural de los dendrogramas. Existen dos rutas principales dependiendo de si se busca una extracción rápida de datos o una visualización que mantenga personalizaciones complejas previas.
La ruta de ggdendro: Extracción y control total
El paquete ggdendro(Vries y Ripley 2024) se especializa en extraer los datos del dendrograma (segmentos, etiquetas y etiquetas de hojas) y convertirlos en una lista de marcos de datos (data frames) mediante la función genérica dendro_data(). Este enfoque es puramente tidy, ya que permite al usuario acceder a los datos de los segmentos con segment() y de las etiquetas con label(), tratándolos como cualquier otra fuente de datos en ggplot2.
Wrapper rápido: La función ggdendrogram() actúa como un envoltorio que genera un gráfico completo en una sola línea de código, permitiendo rotaciones y ajustes de tamaño básicos. Al ser un objeto de clase ggplot, se le pueden sumar capas adicionales o temas como theme_bw() (figura 6.6).
Personalización granular: Para un control total, se pueden usar los datos extraídos con geometrías estándar como geom_segment() y geom_text(). Esto facilita, por ejemplo, crear dendrogramas con líneas triangulares en lugar de rectangulares o aplicar un fondo limpio mediante theme_dendro(), que elimina ejes y cuadrículas innecesarias.
La ruta de dendextend: Preservación de atributos
Por otro lado, dendextend ofrece la función as.ggdend(), diseñada para convertir objetos de clase dendrogram (que ya poseen colores, grosores de línea y estilos de nodos personalizados) en objetos compatibles con ggplot2. A diferencia de ggdendro, esta ruta busca preservar los parámetros gráficos complejos que se hayan definido previamente en el objeto original.
Conversión tabular:as.ggdend() transforma el árbol en un objeto con tres componentes tabulares (segmentos, etiquetas y nodos), lo que permite que ggplot2 interprete automáticamente colores y tipos de línea específicos para cada rama.
Flexibilidad geométrica: Una vez convertido, es posible aplicar transformaciones espaciales avanzadas, como convertir el dendrograma en un gráfico radial mediante coord_polar(theta="x") o invertir los ejes con scale_y_reverse().
Esta dualidad permite elegir entre la simplicidad de extraer datos crudos para construir desde cero con ggdendro, o la potencia de dendextend para llevar una clasificación altamente personalizada al entorno de capas y temas de ggplot2.
Código
library(readxl)library(dplyr)library(tidyr)library(ggplot2)library(ggdendro)library(vegan)datos_amb <-read_excel("datos/datos_ambientales_PNLR.xlsx")# Comandos del paquete {vegan}, {dplyr} y {ggplot2} para graficar promedios y desviación estándar.datos_amb|>filter(Muestreo ==1)|>select(`Corriente (cm/min)`, Salinidad,`Clorofila a mg/m3`,`MO_SST_%`)|>mutate(`Log de Corriente`=log(`Corriente (cm/min)`+1),`Log de Salinidad`=log(Salinidad),`Log de Clorofila`=log(`Clorofila a mg/m3`))|>select(-c(`Corriente (cm/min)`, Salinidad,`Clorofila a mg/m3`))|>decostand(, method ="standardize")|>vegdist(method ="euclidean")|>hclust(, method ="ave")|>ggdendrogram(size =1, theme_dendro =FALSE)+ylab("Distancia euclidiana")+xlab("Sitios")+theme_classic()
Fig. 6.6: Dendograma de la matriz de distancias euclidianas usando paquete ggplot2