El objetivo principal de este laboratorio es introducirlos a la exploración de datos y estadística descriptiva con R y RStudio, las herramientas computacionales que utilizaremos a lo largo del semestre para aprender a aplicar los conceptos más importantes de Estadística Aplicada I, pero en especial, para aprender a procesar y analizar datos reales.
El programa R, sus versiones actualizadas y todos los paquetes con funciones, asi como otra información relevante se encuentre en los repositorios de R conocidos como CRAN (Comprehensive R Archive Network). Los distintos servidores distribuidos en todo el mundo, conforman el CRAN y son conocidos como los CRAN mirrors (de espejo). Para descargar los paquetes requieres antes escoger un CRAN mirror, y la función que te permite escogerlo de una lista que aparece en la consola es chooseCRANmirror. Alternativamente, se pueden descargar paquetes desde otros repositorios, uno muy popular y que estaremos usando en esta asignatura es GitHub.
RStudio es un entorno de desarrollo integrado (IDE) para R. Incluye una consola, editor de comandos y líneas de programación que admite la ejecución directa de código, así como herramientas para graficar, documentar, registrar el historial de comandos ejecutados, acceder a archivos, y muchas cosas más desde la gestión de un espacio de trabajo. RStudio hace que el trabajar con R sea más poderoso, y a su vez simple. Para que tengan una idea, esta guía se escribió desde RStudio.
Las funciones están organizadas en paquetes. El paquete denominado base constituye el núcleo de R y contiene las funciones básicas del lenguaje. Otro paquete muy importante es stats e incluye las funciones estadísticas más importantes y básicas de R. Ambos ya vienen preinstalados en R. Existen muchos paquetes, a medida que se requiera el uso de alguno específico se irá indicando para que lo descarguen e instalen. Por ahora les adelanto el uso de un set de paquetes agrupados en una familia de paquetes muy usados para ordenar, limpiar, modelar, reproducir, comunicar y graficar datos; este grupo de paquetes se les denomina tidyverse. Para instalarlos pueden escribir en la consola:
Código
#Para instalar ggplot2 (realizar gráficos de alta calidad)install.packages("ggplot2")#Para depurar y reordenar bases de datos, instala: tidyrinstall.packages("tidyr")#Para administrar bases de datos: usa dplyrinstall.packages("dplyr")#Para importar datos desde Excel: readxlinstall.packages("readxl")#Para análisis en ecología de comunidades usa veganinstall.packages("vegan")#para estimar simetría y curtosisinstall.packages("moments")#Para instalar todos los paquetes del Tidyverse, incluyendo ggplot2, tidyr, dplyr, etc:install.packages("tidyverse")
Alternativamente, puedes usar del menú superior la opción Tools/install packages…, se desplegará una ventana para que escribas el nombre del paquete a instalar. Los paquetes se instalan una sola vez, siempre que estes en el mismo computador. Para usarlos debes incluirlos en tu sesión de trabajo cada vez que se inicia la sesión. Esto se logra con la función library:
Código
#|eval: falselibrary("tidyverse")
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.1 ✔ tibble 3.3.1
✔ lubridate 1.9.4 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Hagamos un análisis exploratorio a los datos de los pinguinos de la Antártida del género Pygoscelis. Lo primero que debe hacer es instalar el paquete de datos palmerpenguins y cárguelo en su sesión. Luego haga lo siguiente:
Busque en la pestaña Help qué es palmerpenguin.
Identifique la base de datos penguins y cárguela en su ambiente global con data(penguins).
Identifique cuántas variables hay, cuál es la naturaleza de cada una de ellas (tipo de variable, escala), así como cuáles pueden ser consideradas causales y cuáles respuesta.
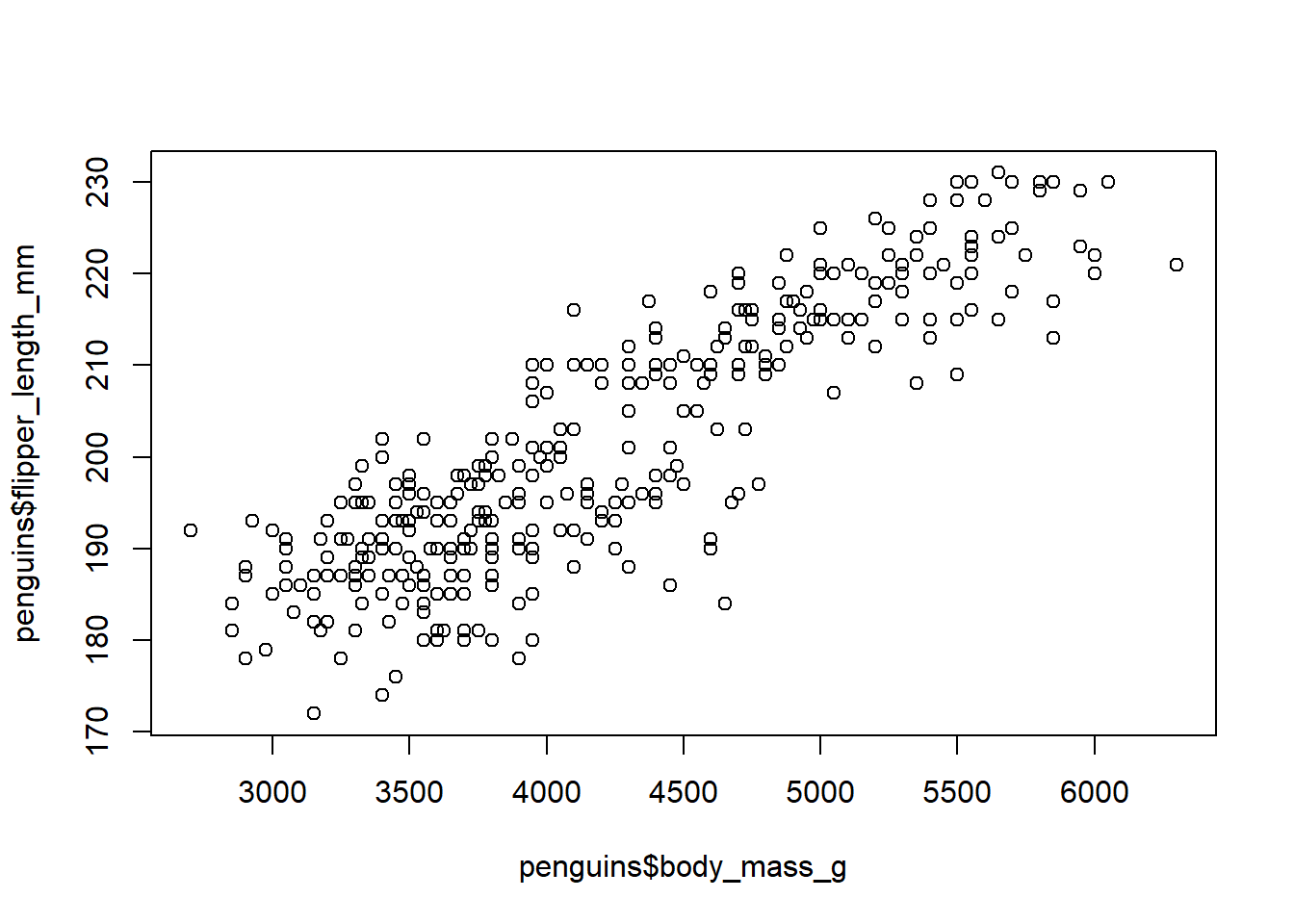
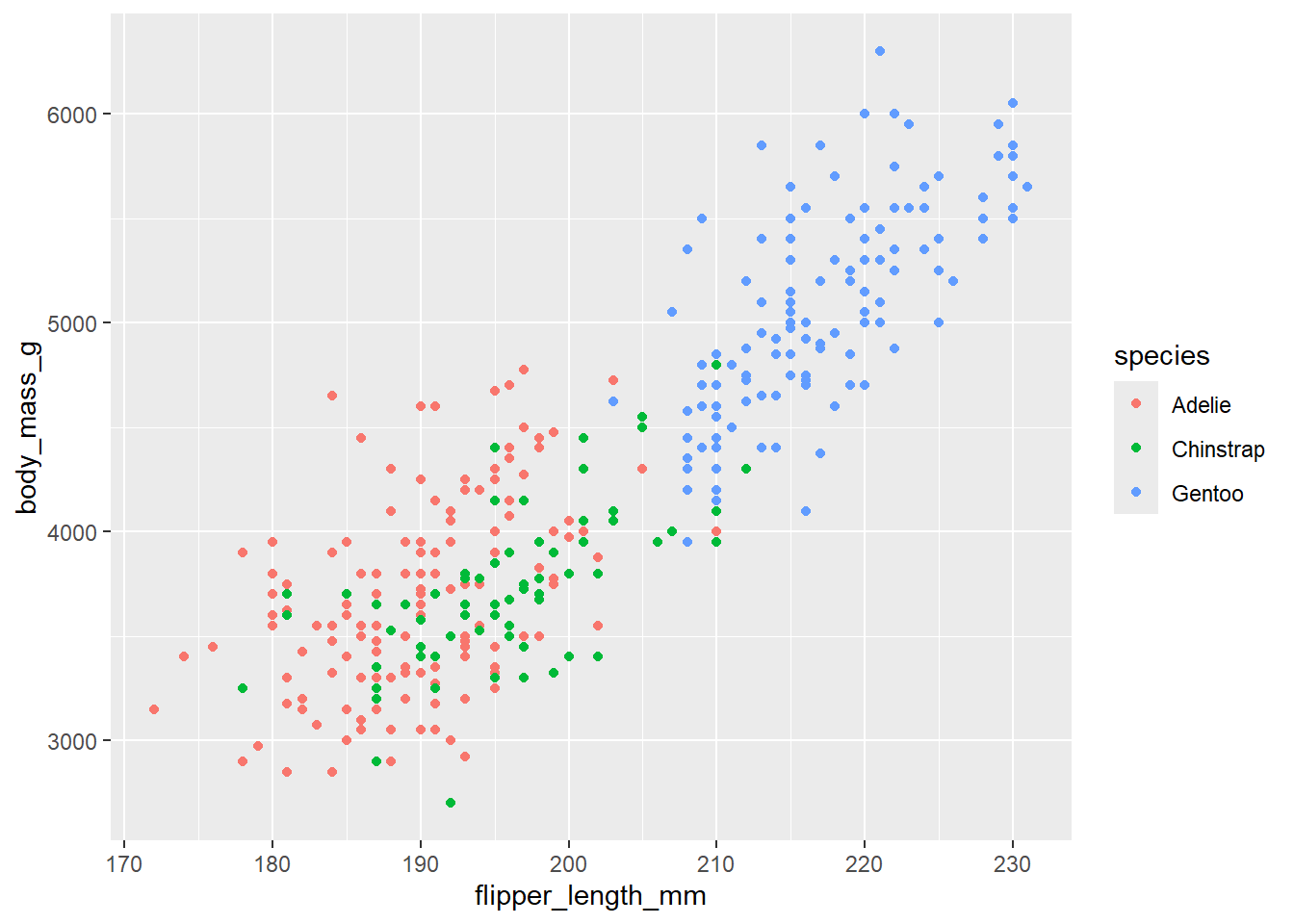
Efectue un gráfico de dispersión entre las variables body_mass_g y flipper_lemgth_mm. Mida el grado de asociación ¿cómo lo haría? Una forma de hacer estas cosas es graficando la asociación, y estimando la correlación (método que se desarrollará en otro laboratorio, pero acá es pide con fines demostrativos)
Código
#|eval: falselibrary(palmerpenguins)
Adjuntando el paquete: 'palmerpenguins'
The following objects are masked from 'package:datasets':
penguins, penguins_raw
Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_point()`).
Código
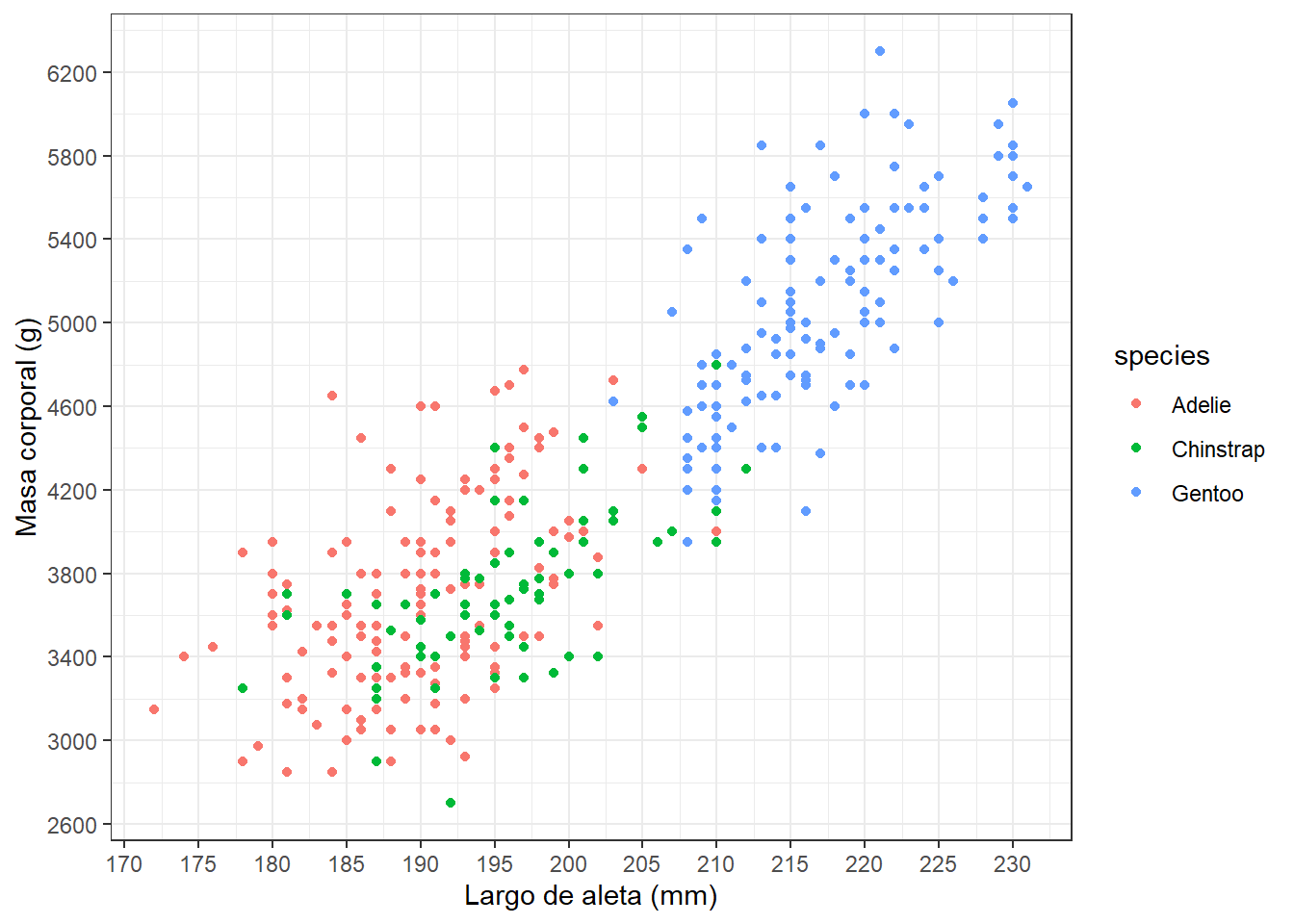
#Mejoremos con capaspp +theme_bw()+xlab("Largo de aleta (mm)")+ylab("Masa corporal (g)")+scale_y_continuous(breaks =seq(2600,6400,400))+scale_x_continuous(breaks =seq(170,240,5))
Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_point()`).
Código
#¿cuál gráfico le gustó más?
Llegados a este punto, vamos hacer algo de estadística descriptiva. Esta es la parte que deberán entregar como tarea. Calculen promedio, varianza, desviación estandar, valor mínimo y máximo, cuartiles, simetría y curtosis a la variable masa corporal. Usen para ello las funciones recomendadas y responda las siguientes preguntas:
Código
#|eval: false# Para facilitar cálculos, vamos a remover los datos sin registro (identificados con NA), usando el siguiente código:penguins2 <- penguins %>%na.omit()
Busca y aplica una función que ejecute la linea de comando anterior. PISTA: escribe ?mean en la consola y enter para ampliar tu búsqueda.
Calcula la mediana de la masa corporal usando la función correspondiente.
Calcula la varianza y desviación estándar de la masa corporal usando el comando var()
¿Cuál es la diferencia entre estas dos fórmulas? ¿Representan lo mismo?
sum((xx-mean(xx))^2)/length(xx)
sum((xx-mean(xx))^2)/(length(xx)-1)
Con base en el valor de la varianza y usando operadores aritméticos, calcula la desviación estándar de la masa corporal. Confirma tu resultado usando la función sd().
Explore el rango de la masa corporal identificando mínimos y máximos con la función min() y max(), respectivamente.
Ahora estime los cuartiles de la masa corporal con la función quantile()
Describa la forma de la distribución de la masa corporal usando la simetría y curtosis con las funciones skewness() y kurtosis().
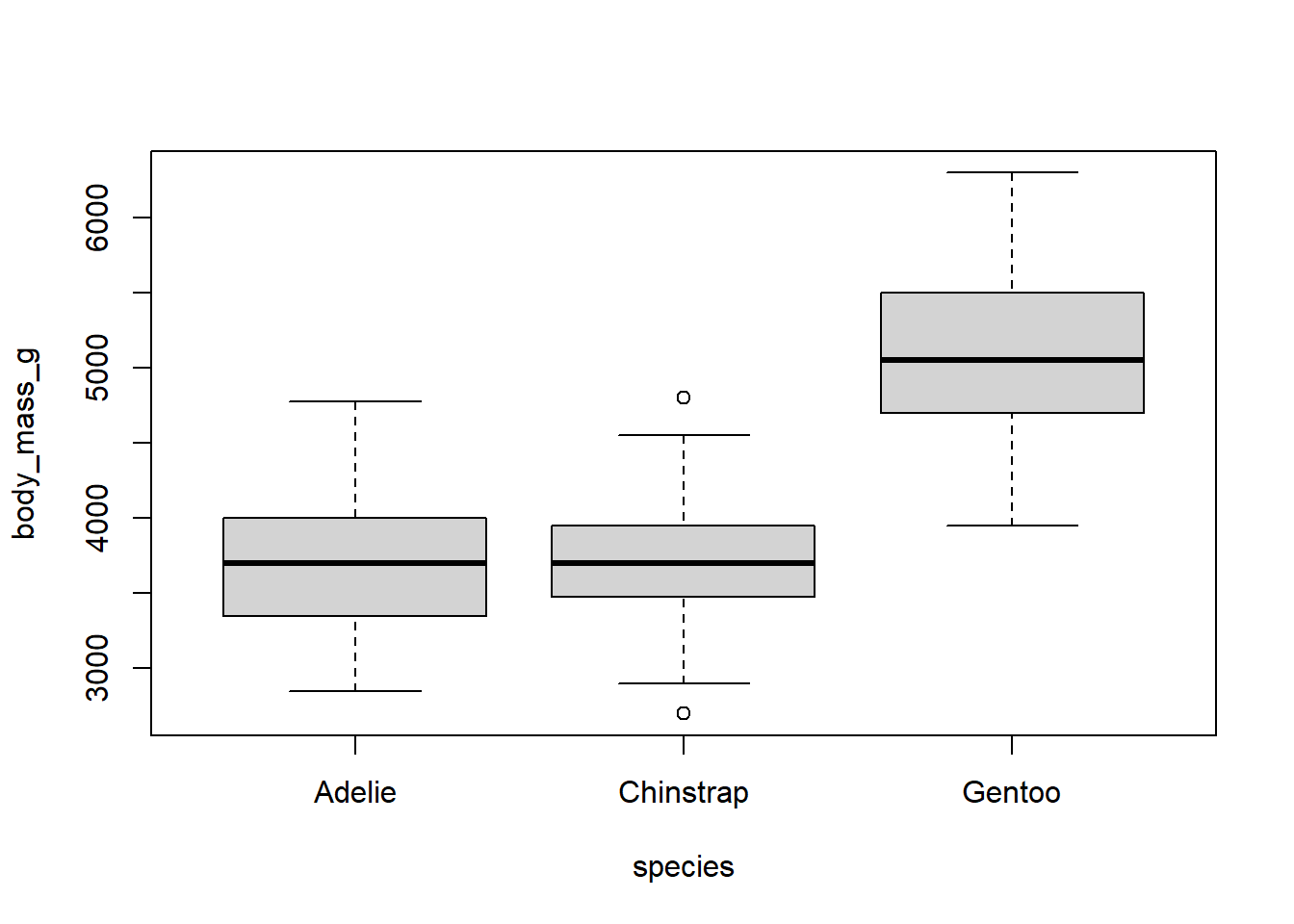
Todas estas estimaciones ignoran las posibles diferencias en la masa corporal entre las especies. ¿Qué le dice este gráfico?
Código
#|eval: falseboxplot(body_mass_g~species, data = penguins2)
Calcule estos estimadores para cada especie usando el paquete dplyr y sus funciones group_by() y summarize(). Estas líneas de comando lo ayudarán (interprete los resultados):
Usando como guía el libro digital R Graphics Cookbook, genere: (i) una distribución de frecuencias con histograma, (ii) una distribución de frecuencias basada en densidad, (iii) un diagrama de cajas que incluya promedio. En los tres casos la masa corporal debe distinguirse por especie.