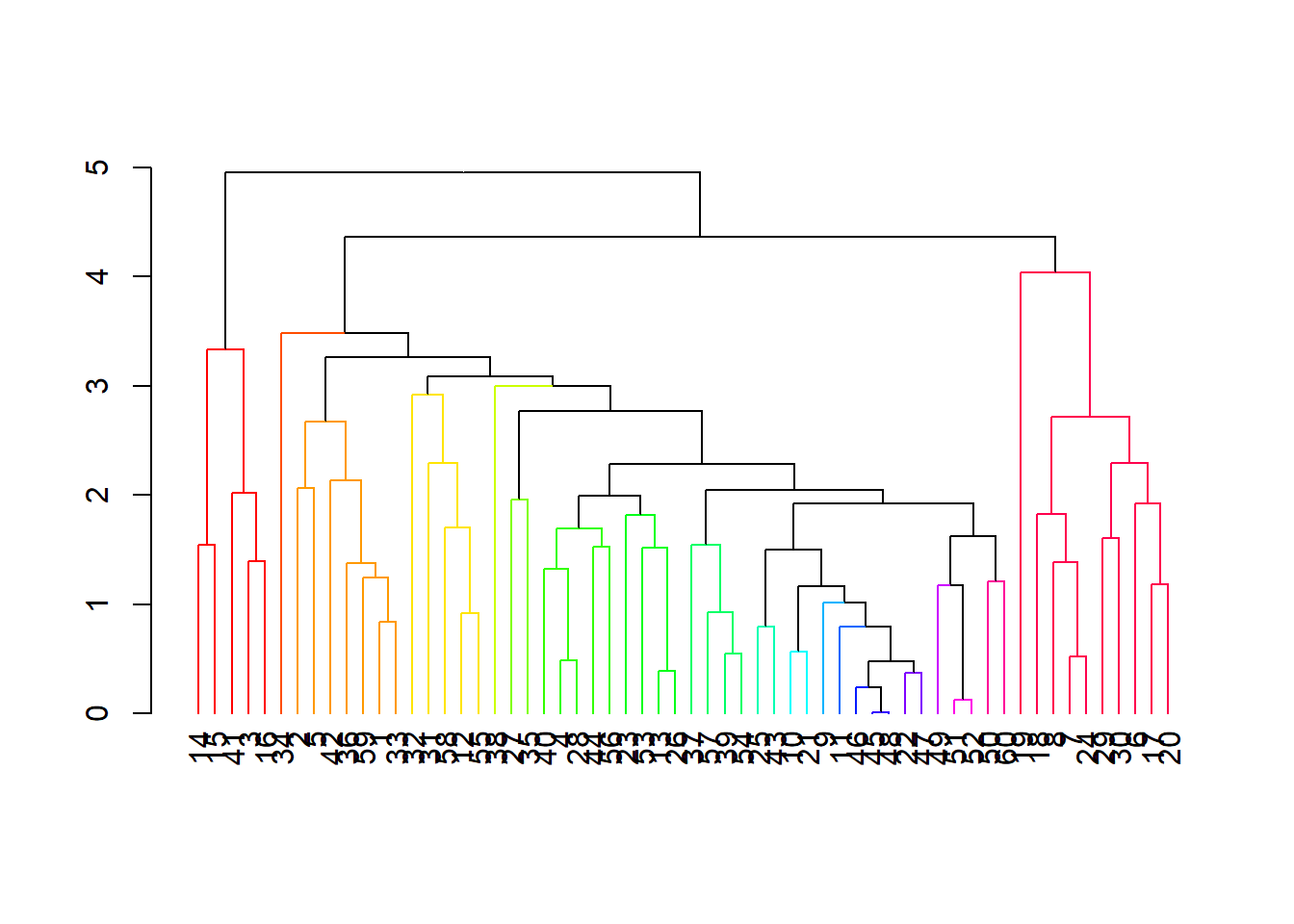
7.1 Prueba al perfíl de Similitudes (SIMPROF test)
El análisis de clasificación jerárquica posee una limitación intrínseca: su algoritmo siempre producirá un dendrograma con agrupamientos, incluso si los datos consisten enteramente en números aleatorios sin estructura biológica o ambiental real. Este artefacto puede ser apreciado en la figura 7.1. Esta figura representa un dendrograma jerárquico construido sobre 10 muestras simuladas, cada una con cinco variables cuyos valores en cada muestra se generaron con números aleatorios, todos en el mismo rango. En el dendrograma se aprecia una configuración de grupos que es completamente irrelevante considerando que todas las variables fueron medidas en todas las muestras y que todas tienen el mismo rango de valores aleatorios generados. En este caso podemos claramente identificar que los grupos son consecuencia de un evento aleatorio y no representan una estructura multivariada heterogénea real. Con base en esta demostración surje la duda ¿cómo podemos identificar cuál agrupamiento es real y no consecuencia del azar?.
Código
#|fig-colwidths: [60,40]#|message: false#|warning: false# Datos aleatorios con misma estructuraset.seed(123) # semilla para reproducibilidaddat <-data.frame(a =runif(n =10, min =1, max =10),b =runif(n =10, min =1, max =10),c =runif(n =10, min =1, max =10),d =runif(n =10, min =1, max =10),e =runif(n =10, min =1, max =10))# Distancia euclidianad <-dist(dat) #Dendrograma jerárquicocluster <-hclust(d = d, method ="complete") plot(x = cluster, hang =-0.1, main ="",sub ="",xlab ="Grupos",ylab ="Distancia euclidiana")
Fig. 7.1: Dendrograma construido a partir de la generación de diez muestras simuladas con cinco variables y números aleatorios en el mismo rango (1-10)
Históricamente, la decisión de dónde “cortar” el dendrograma para definir los grupos reales recaía en la discreción del investigador, lo que introducía una subjetividad problemática que podía derivar en la sobreinterpretación de variaciones aleatorias del muestreo como si fueran patrones ecológicos reales. Para evitar este sesgo, es imperativo utilizar un criterio objetivo basado en pruebas de hipótesis que permitan descartar grupos falsos y asegurar que solo se interpreten subdivisiones donde exista una evidencia estadística de estructura multivariada que genera grupos.
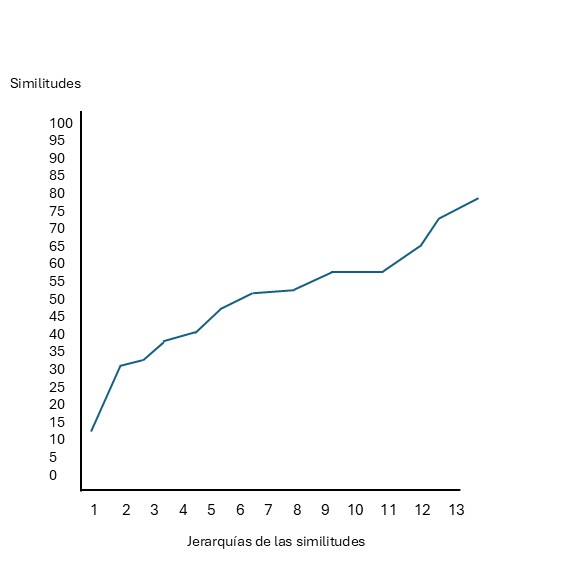
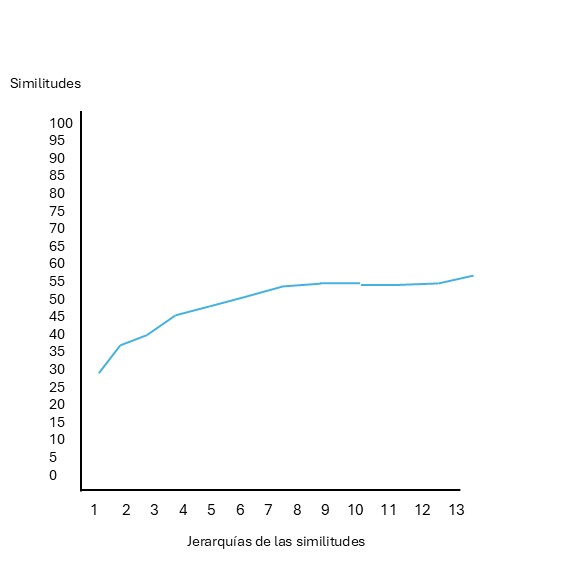
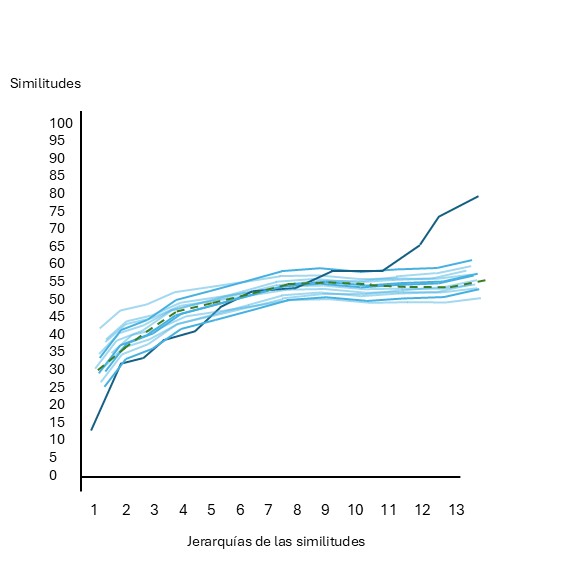
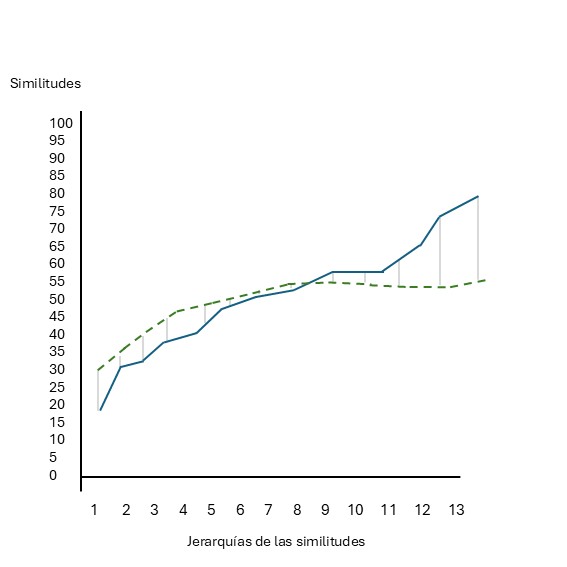
Una herramienta no paramétrica para este propósito es la Prueba de Perfil de Similitud (SIMPROF) propuesta por Clarke, Somerfield, y Gorley (2008). La lógica de la prueba se basa en la construcción de un perfil de similitudes real de los datos: para esto se calculan las similitudes entre todos los pares de muestras de un grupo, se ordenan de menor a mayor y se grafican contra su jerarquía. Si existe una estructura genuina, el perfil mostrará un exceso de similitudes muy bajas (entre muestras diferentes) y muy altas (entre muestras similares), resultando en una curva con una pendiente pronunciada figura 7.2. Por el contrario, si no hay estructura, las similitudes variarán aleatoriamente alrededor de una media común, generando un perfil mucho menos empinado figura 7.3.
Fig. 7.2: Perfil de similitud con clara estructura de grupos
Fig. 7.3: Perfil de similitud sin clara estructura de grupos
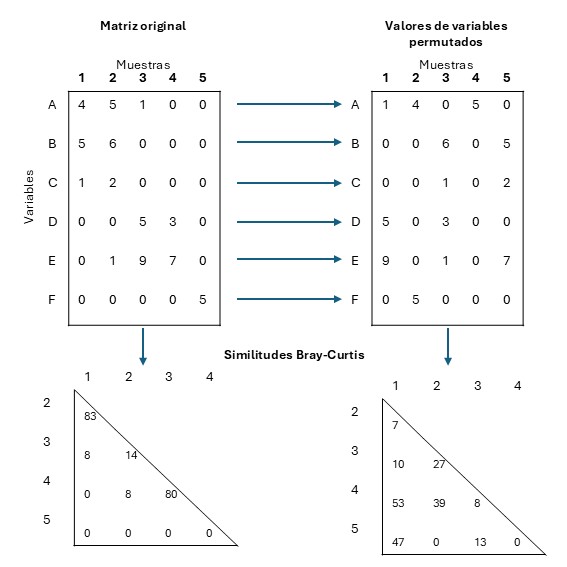
Ahora, distinguir entre un perfíl con pendiente pronunciada y uno con poca pendiente no siempre es intuitivo, seguimos estando en el escenario de definir subjetivamente qué tan fuerte es la pendiente como para considerarla correcta. Para determinar si el perfil observado tiene pendiente pronunciada se debe comparar contra un perfíl de referencia que asuma que no hay estructura de grupo. Para lograr esto, el método emplea la aleatorización de variables. Este procedimiento, computacionalmente intensivo, intercambia los valores de cada variable de forma independiente entre todas las muestras, lo que destruye cualquier asociación o sinergia entre las muestras figura 7.4. El principio es simple: si el grupo es real, y las muestras corresponden genuinamente al mismo grupo, los valores de sus descriptores pueden ser intercambiables entre todos sin generar ruptura en el perfíl de similitud. Este procedimiento de aleatorización se repite muchas veces, típcamente unas mil veces, siendo que para cada arreglo aleatorio se contruya el perfíl de similitud, por lo tanto se pueden generar mil perfiles de similitud figura 7.5. El siguiente paso es calcular la tendencia promedio de esos perfiles simulados, y consiste básicamente en promediar el valor de similitud generado con aleatorizaciones para cada jerarquía. Al conectar estos promedios, se genera una línea de tendencia central, que será útil para comparar el comportamiento del perfil real. Con esta línea primedio se asume el perfíl de similitud para la hipótesis nula de que no existe una estructura multivariada diferente entre los miembros del grupo (es decir, que todas las muestras provienen de la misma población y son muy similares). En este escenario, el perfil real no debería diferir de los perfiles generados mediante las permutaciones aleatorias ya que todas las características de cada muestra son en escencia las mismas entre todas las muestras.
Fig. 7.4: Proceso de aleatorización de valores de una matriz real a una asumiendo que no hay estructura de grupos
Fig. 7.5: Perfil de similitud sin clara estructura de grupos
La construcción de la prueba de hipótesis culmina con el estadístico 𝜋, que se define como la sumatoria de las desviaciones absolutas entre el perfil real y el promedio de los perfiles permutados figura 7.6. Es decir, se suman las diferencias observadas para cada jerarquía entre el perfíl real y el promedio de los perfiles aleatorizados. Para obtener un valor de probabilidad (p) que permita descartar la hipótesis nula, se genera una segunda serie de perfiles aleatorios (p. ej. 999), las respectivas desviaciones de estos nuevos perfiles aleatorios con el promedio de perfiles aleatorizados generarán 999 valores de 𝜋aleatorios. Seguidamente se calcula la probabilidad de \(\pi\) de pertenecer a una distribución de valores 𝜋aleatorios asumiendo la hipótesis nula cierta. Si el valor de \(\pi\) de los datos reales es mayor que el obtenido por azar en la gran mayoría de las permutaciones (por ejemplo, el 95% de los valores 𝜋aleatorios), se rechaza la hipótesis nula con un 5% de probabilidad de errar, otorgando una “licencia” estadística para interpretar esa subdivisión del dendrograma.
Fig. 7.6: Proceso de aleatorización de valores de una matriz real a una asumiendo que no hay estructura de grupos
{#fig-simprof4
Esta aplicación secuencial en los nodos de un dendrograma se conoce originalmente como SIMPROF Tipo 1.
7.2 SIMPROF EN R: clustsig
El paquete clustsig fue desarrollado en 2010 como una implementación en R de la rutina SIMPROF que solo estaba disponible en el software PRIMER. Sus funciones principales permiten evaluar, mediante permutaciones, si los grupos observados en un dendrograma presentan una estructura interna significativamente distinta de la esperada bajo un modelo nulo de ausencia de agrupamiento, proporcionando así un criterio objetivo para la delimitación de clústeres. Entre sus funciones más utilizadas se encuentran simprof. Es importante señalar que clustsig ya no se encuentra disponible en el repositorio activo de CRAN, ya que fue archivado; sin embargo, su código fuente puede instalarse manualmente utilizando la versión 1.1 disponible en los archivos históricos de CRAN o directamente desde su repositorio en GitHub, lo que permite seguir empleándolo en flujos de trabajo reproducibles con versiones compatibles de R.
Para femostrar la funcionalidad de clustsig, usemos el juego de datos ambientales de Guerra-Castro et al. (2021). Estos datos consiste en promedios de 16 variables fisicoquímicas del agua a lo largo de 12 localidades de una laguna costera, evaluado en cinco momentos durante 2009 y 2010. Como hicimos en la Sección 3.2, solo representaremos las relaciones de las localidades usando cuatro variables: clorofila (mg/m3), velocidad de corriente (cm/min), porcentaje de materia orgánica en sólidos suspendidos, y salinidad. Estas variables recibieron un trnasformaciones individuales y luego fueron normalizadas. Seguidamente se aplicó la función simprof que ya incluye los argumentos necesarios para estimar la matriz de distancias a cada proceso de aleatorización. El resultado que genera la función se presenta en forma de lista, indicando al número de grupos significativos, y el ID de las muestras que pertenecesn a cada grupo. No obstante, la forma más práctica de apreciar el resultado es con la función simprof.plot que genera un dendrograma jerárquico con grupos identificados con colores diferentes (figura 7.7).
Código
# Lectura de datos y aplicación de pretratamientoslibrary(readxl)library(dplyr)library(vegan)datos_amb <-read_excel("datos/datos_ambientales_PNLR.xlsx")dat <- datos_amb|>select(`Corriente (cm/min)`, Salinidad, `Clorofila a mg/m3`, `MO_SST_%`)|>mutate(`Log de Corriente`=log(1+`Corriente (cm/min)`),`Log de Salinidad`=log(Salinidad),`Log de Clorofila`=log(`Clorofila a mg/m3`))|>decostand(, method ="standardize")|>as.data.frame()# aplicación de función simprof de clustsiglibrary(clustsig)resultado <-simprof(data = dat, num.expected =1000, num.simulated =999, method.distance ="euclidean", alpha =0.05)#Dendrograma con grupos significativos idantificadossimprof.plot(resultado)
'dendrogram' with 2 branches and 60 members total, at height 4.95139
Fig. 7.7: Evaluación con SIMPROF y el paquete clustsig al dendrograma construido con distnacias euclidianas a cuatro variables pretransformadas 12 localidades de una laguna costera, evaluadas cinco veces entre 2009 y 2010
Clarke, K. Robert, Paul J. Somerfield, y Raymond N. Gorley. 2008. «Testing of null hypotheses in exploratory community analyses: similarity profiles and biota-environment linkage». Journal Article. Journal of Experimental Marine Biology and Ecology 366 (1): 56-69. https://doi.org/https://doi.org/10.1016/j.jembe.2008.07.009.
Guerra-Castro, Edlin J., Jesús Eloy Conde, Amalia Barcelo, y Juan J. Cruz-Motta. 2021. «Variation in fouling assemblages associated with prop roots of Rhizophora mangle L. in the Caribbean: The role of neutral and niche processes». Journal Article. Austral Ecology 46 (6): 991-1007. https://doi.org/https://doi.org/10.1111/aec.13071.
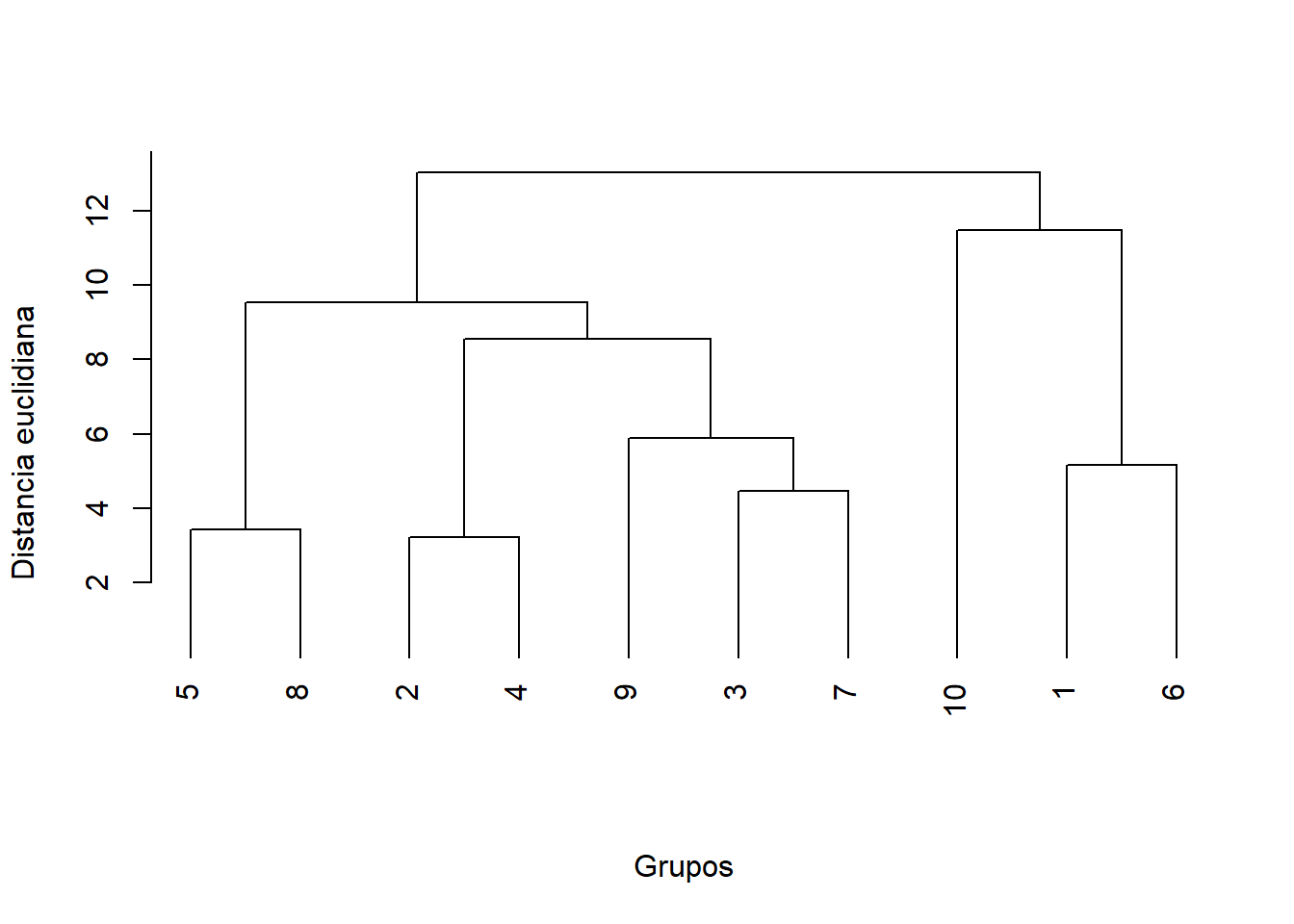
 {#fig-simprof4
{#fig-simprof4