Los sistemas naturales suelen ser complejos, están compuestos por múltiples componentes bióticos, físicos, químicos y sociales que varían de lugar a lugar y de momento en momento (figura 1.1). Como científicos, típicamente requerimos describir detalladamente a estos sistemas. Por ejemplo, necesitamos saber cómo cambia la composición de especies de un lugar a otro, o requerimos comparar las características ambientales de un lugar sujeto a impactos ambientales respecto de lugares poco perturbados. Los propósitos para responder preguntas de esta índole son varios, pero pueden destacar, por ejemplo, la necesidad de crear una reserva natural, o de evaluar la efectividad de una reserva en la conservación de la biodiversidad, o detectar un impacto ambiental sobre un ecosistema generado por un proyecto de desarrollo industrial. En otras ocasiones nos interesa identificar los procesos que generan las diferencias espaciales o temporales en los ecosistemas, y para ello diseñamos experimentos en que se evalúan hipótesis a través del método científico. No obstante, debido a la variabilidad natural que caracteriza a los ecosistemas, se requieren de técnicas cuantitativas robustas que garanticen aproximarnos de forma objetiva a la realidad.
Fig. 1.1: Representación de la complejidad de un ecosistema. Imagen generada por DALL-E usando las palabras arrecife coralino, pescadores, tormenta (07/09/2023)
Para elegir las técnicas cuantitativas adecuadas es necesario poder reconocer los componentes fundamentales de la hipótesis que estamos evaluando. Es decir, debemos reconocer cuál es la población sobre la cual vamos a hacer inferencia y su contexto, debemos reconocer también cuál es la variable que responderá al mecanismo asociado al proceso enunciado en la hipótesis, así como la variable que representa al mecanismo causal. En este punto empiezan las definiciones críticas que deben ser bien definidas desde el inicio del estudio, de las que podemos destacar población objetivo, variables y población estadística.
Tip¿qué es una hipótesis?
Es una predicción respecto a un evento desconocido, justificado con una teoría que permite explicar las observaciones originales. Es fundamental en el desarrollo del Método Científico, y por lo tanto, en orientar sobre los tipos de análisis estadísticos que se requerirán en el estudio (Underwood 1990).
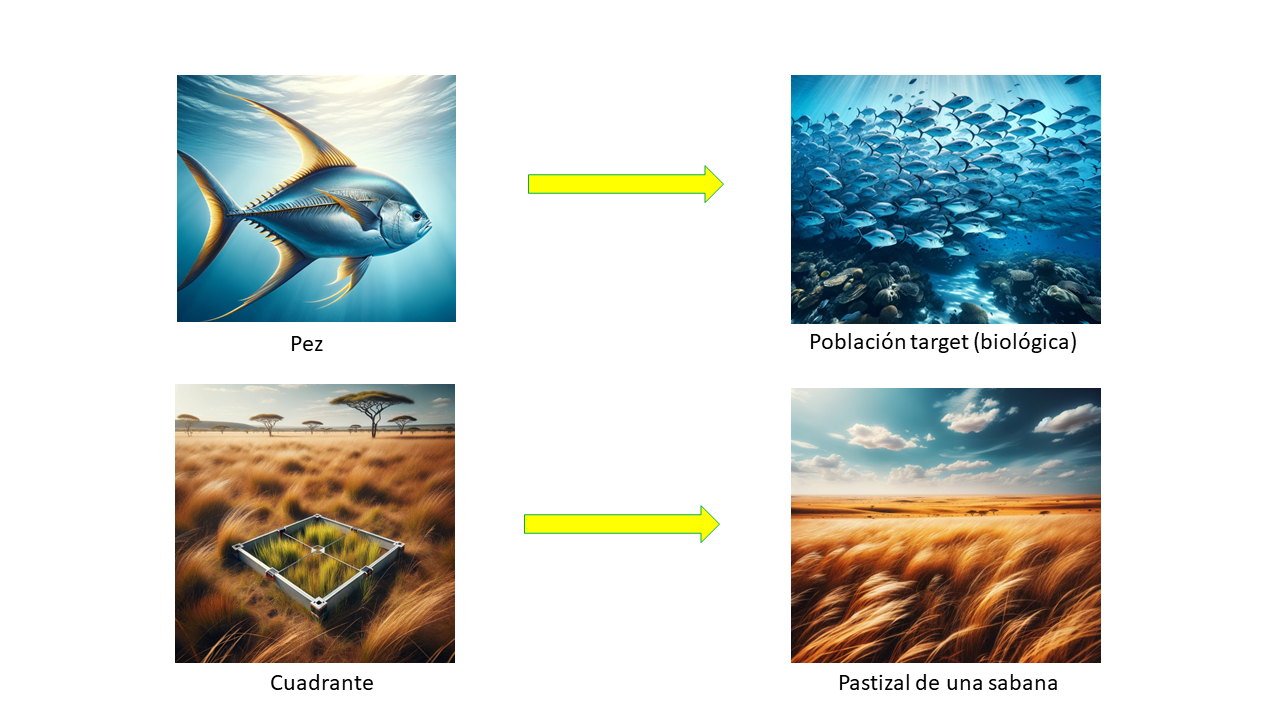
La población objetivo representa a todos los objetos o elementos sobre los cuales se realizará inferencia estadística. En ciencias naturales, estos objetos pueden ser los individuos de una población biológica, todas las especies de una comunidad ecológica, también pueden ser todo el suelo de un pastizal (figura 1.2). En sí, la población objetivo representa el componente del ecosistema que debe ser descrito. Esta tiene que estar muy bien definida en espacio y tiempo, ya que sus límites tienen implicaciones importantes en el diseño del muestreo, pero sobre todo en la inferencia que se haga, el alcance y generalidad de la conclusión. En la práctica, los objetos de una población objetivo pueden ser elementos naturalmente discretos (p. ej. peces de un cardumen, árboles en un bosque, rocas de un acantilado), o artificialmente definidos por el investigador (p. ej., núcleos de sedimento, foto-trampas, parcelas, transectos, etc.) (figura 1.2).
Fig. 1.2: Población objetivo y sus objetos. En la parte superior se representa una población de peces sobre la que se hará inferencia estadística estudiando un subconjunto de objetos (peces). En la parte inferior un pastizal que será caracterizado a través de cuadrantes dispuestos aleatoriamente. Las cuatro imágenes fueron generadas con un generador de imágenes de ChatGPT 4.0
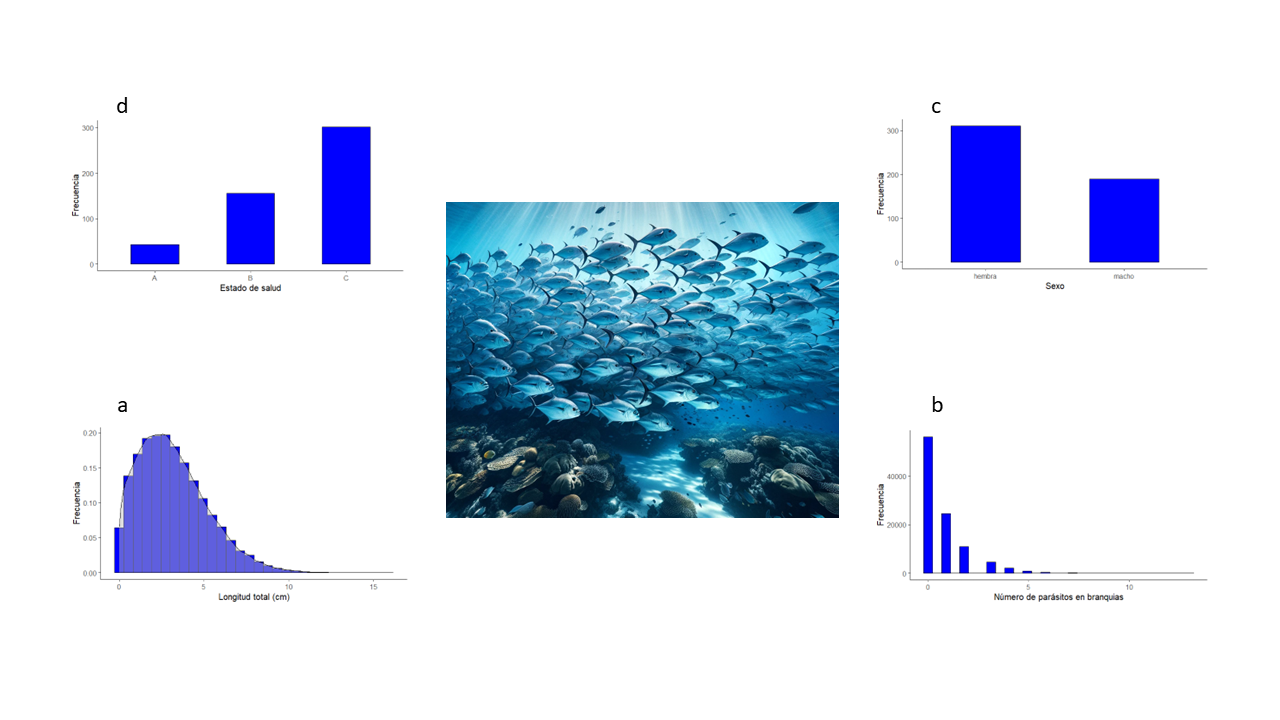
Fig. 1.3: Representación de los principales tipos de variables que se pueden medir o describir en un mismo objeto y su representación en una población estadística
Las variables son atributos de una población objetivo cuyas expresiones cambian de objeto en objeto. En ciencias naturales, las variables pueden ser de diferentes tipos: (1) categóricas de atributo (p. ej., sexo: hembra, macho), (2) categóricas de rango (p. ej. estado de salud: mal, regular, bien), variables numéricas continuas (p. ej. tamaño: 23.25 cm, 19.54 cm, 21.97 cm, etc.), variables numéricas discretas (p. ej. número de parásitos en branquias: 3, 4, 5, 6, etc. ) (figura 1.3). Otras variables pueden ser derivadas de la relación matemáticas de otras inicialmente medidas (p. ej.: densidad de parásitos por branquia: 1.5, 1.72, 2.23) o transformadas por alguna función matemática (p. ej., logaritmo del tamaño: 3.14, 2.97, 3.09, etc.). Otras variables con una escala peculiar son las de tiempo (p. ej. fecha, hora), y variables espaciales (p. ej. coordenadas geográficas).
Las variables son componentes fundamentales de las hipótesis de investigación, ya que normalmente se busca identificar la relación entre las características de una variable en una población objetivo según las características de otras variables de la misma población objetivo o de otra población objetivo. Por ejemplo, puede haber interés en evaluar la diferencia en el tamaño corporal (variable numérica continua) en una población de peces de una región en particular (población objetivo) en función del sexo (variable categórica de atributo de la misma población objetivo).
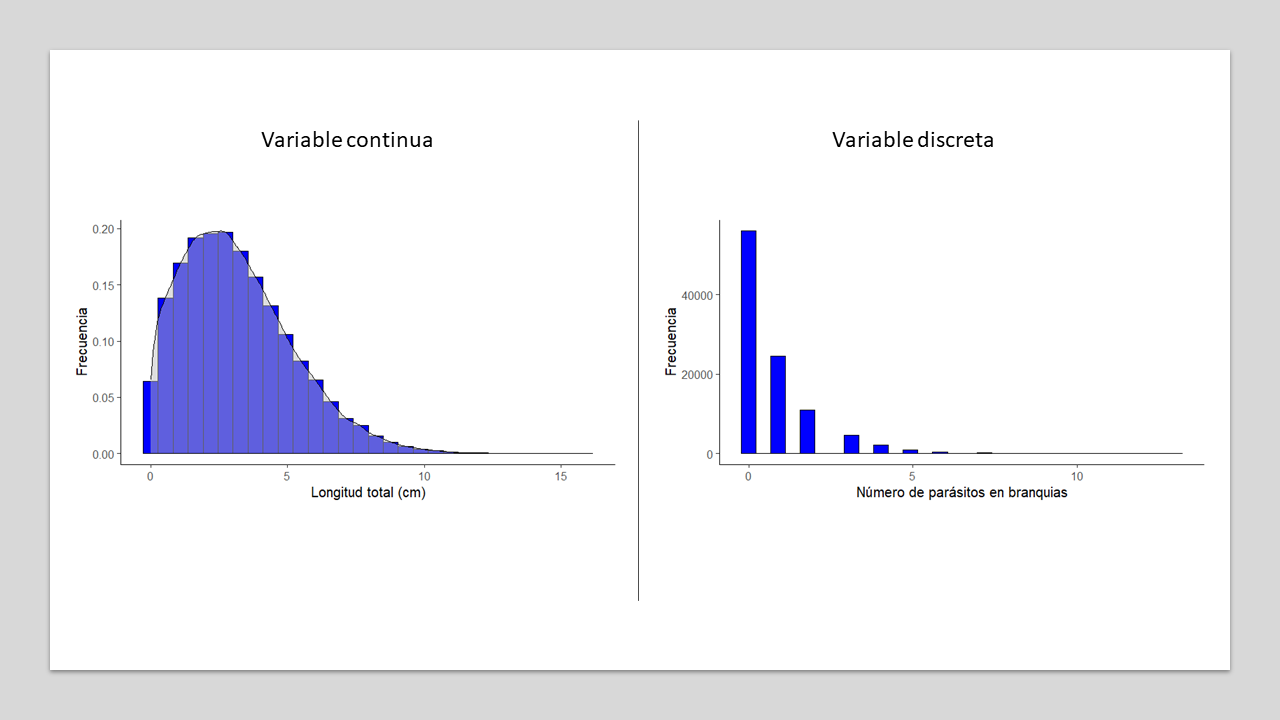
Esto nos lleva a presentar otro tipo de definición de población, ahora en el contexto estadístico: La población estadística. Esta representa todos los valores que una variable puede tener en una población objetivo. Dicho de otra forma, constituye el conjunto de expresiones de una variable o atributo específico en la población objetivo. Por lo tanto, una población objetivo que tenga, digamos, 10 variables, tendrá 10 poblaciones estadísticas, una para cada variable. Por otra parte, cada elemento de la población objetivo tendrá, bajo ciertas condiciones de estabilidad, un único valor para esa variable, por lo que la población estadística tendrá un tamaño igual al del número de elementos en la población objetivo. Todas las expresiones de la variable pueden ser contabilizadas según la frecuencia con que ocurren, y representadas gráficamente en forma de histograma. Este tipo de gráfico refleja la frecuencia relativa (proporciones), o absoluta, con que se expresa cada valor, o rango de valores, en el juego de datos. Esto se ilustra para tres variables cuantitativas (dos continuas, una discreta) en la figura 1.4.
Fig. 1.4: Población Estadística a partir de cada posible valor de la variable en la población objetivo
En estadística, la distribución de frecuencias con que se expresa una variable estará definida por los parámetros estadísticos poblacionales como el promedio (µ), la varianza (𝜎2), la simetría (𝛾1) y curtosis (𝛾2). Para poder efectivamente identificar si la hipótesis de investigación se cumple, debemos conocer la magnitud de estos parámetros. No obstante, calcular estos parámetros implicaría tener acceso a cada uno de los objetos o elementos de la población objetivo y eso es, en la inmensa mayoría de los casos, imposible. Imagine que usted debe cuantificar el tamaño promedio de los peces de una población en una reserva natural; para ello se deben capturar y medir a todos los peces de la zona de estudio de interés. Esto es logísticamente muy difícil de lograr, pero en caso fuese factible, representa un conflicto ético sobre el impacto negativo del estudio sobre la población de peces (en la gran mayoría de las veces, para medir el tamaño de un pez hay que sacrificarlo). Por esta razón los parámetros se deben estimar a partir de un subconjunto de objetos (individuos en el ejemplo de los peces) obtenidos a través de un muestreo o experimento. Básicamente, con medir las magnitudes con que se expresa la variable de interés en un número reducido de individuos de la población es posible hacer inferencia sobre las magnitudes de los parámetros de la población. Este paso es crítico, ya que se debe garantizar que los objetos elegidos representen las propiedades reales de la población; es decir, que el promedio, la varianza, la simetría y curtosis estimados de la muestra sean lo más cercano posible a los parámetros (desconocidos) de la población. Esto se logra a través de un muestreo representativo, cuyas propiedades fundamentales es que sea preciso y certero.
Tip¿qué es un muestreo representativo?
Es un proceso fundamental en la investigación científica, que implica seleccionar una muestra de elementos o individuos de una población más grande con el propósito de obtener conclusiones precisas y aplicables a toda la población. En términos estadísticos, un muestreo representativo se define como un método en el cual cada elemento en la población tiene una probabilidad conocida y no nula de ser seleccionado para formar parte de la muestra.
La importancia de un muestreo representativo en biología, ecología y ciencias naturales radica en que nos permite estudiar de manera efectiva y eficiente poblaciones grandes y diversas de organismos vivos, comunidades o ecosistemas. Son dos los aspectos claves de un muestreo representativo:
Selección Aleatoria de elementos: Para lograr representatividad, es esencial que la selección de la muestra se realice de manera aleatoria. Con esto se evita sesgos (voluntarios o involuntarios) en la selección de los sitios y muestras. La selección aleatoria implica que cada miembro de la población tiene una probabilidad igual de ser elegido. En ecología y ciencias ambientales, se debe fomentar el diseño de muestreos aleatorios (Smith, Anderson, y Pawley 2017).
Tamaño de la Muestra Adecuado: El tamaño de la muestra debe ser lo suficientemente grande como para que refleje con precisión la variabilidad presente en la población. Un tamaño de muestra pequeño puede llevar a conclusiones poco fiables (Guerra-Castro et al. 2021).
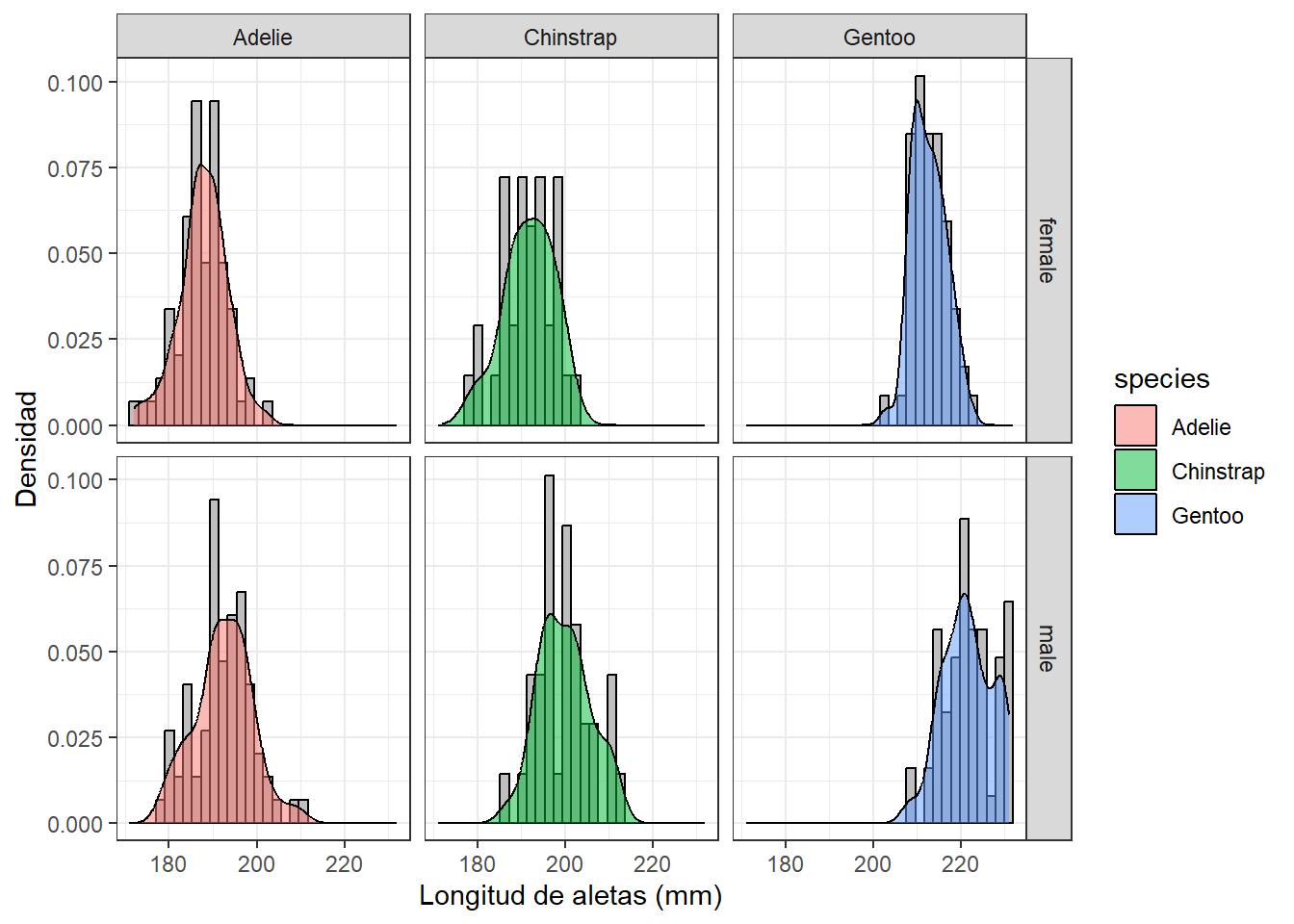
Por ejemplo, en la figura 1.5 se presenta la distribución de frecuencia (y función de densidad) del tamaño de las aletas (variable continua) de 344 pingüinos (objetos) divididos en tres especies (variable categóricas de atributo) y el sexo (variable categórica de atributo), muestreados entre 2007 y 2009 en las islas del Archipiélago Palmer, en el Antártida (Horst, Hill, y Gorman 2020). Vamos asumir que las muestras son representativas, por lo que las diferencias en el tamaño de la aleta que se observan en la figura 1.5 efectivamente reflejan las diferencias en el tamaño de aleta que existen en los pingüinos del Archipiélago Palmer ente 2007 y 2009.
Código
# Importar datos del paquete {palmerpenguins}data("penguins")# Comandos del paquete {dplyr} y {ggplot2} para graficar la distribución de frecuencia para el largo de aleta de cada especie de pingüino.penguins|>drop_na()|>ggplot(aes(x = flipper_length_mm, y = ..density..)) +geom_histogram(fill ="grey75", colour ="black") +geom_density(aes(fill = species), alpha = .5)+facet_grid(sex ~ species)+xlab("Longitud de aletas (mm)")+ylab("Densidad")+theme_bw()
Fig. 1.5: Estimaciones de parametros estadísticos a tres poblaciones de pingüinos en el Archipiélago Palmer, Antártida
Noten como difiere sutilmente la tendencia central a lo largo del eje x (Longitud de aletas en mm) según la especie. Específicamente, Gentoo (Pygoscelis papua) tiende a tener aletas mas grandes que Chinstrap (Pygoscelis antarcticus) y Adelie (Pygoscelis adeliae). También se aprecia que los machos tienden a tener aletas más grandes que las hembras. En todos los casos, la variabilidad parece ser similar, y no se aprecia una tendencia de asimetría en las distribuciones. En la tabla 1.1 se representan las estimaciones estadísticas de los cuatro parámetros estadísticos. A partir de estas estimaciones, ya se pueden identificar potenciales diferencias entre especies y sexos, y con ello formular hipótesis sobre las diferencias morfométricas.
Código
# Comandos del paquete {dplyr} para estimar los parámetros estadísticos promedio, desviación estándar, simetría y curtosis al largo de aleta de cada especie de pingüino.kable(penguins|>drop_na()|>group_by(species, sex)|>summarise("Promedio"=round (mean(flipper_length_mm),2),"Desv. Estándar"=round(sd(flipper_length_mm),2),"Simetría"=round(skewness(flipper_length_mm),2),"Curtosis"=round(kurtosis(flipper_length_mm),2) ))
Tabla 1.1: Estimadores estadísticos (promedio, desviación estándar, simetría y curtosis) al tamaño de la aleta de 344 pingüinos del Archipiélago Palmer, clasificados en tres especies y dos sexos
species
sex
Promedio
Desv. Estándar
Simetría
Curtosis
Adelie
female
187.79
5.60
-0.30
3.49
Adelie
male
192.41
6.60
0.04
3.01
Chinstrap
female
191.74
5.75
-0.41
2.68
Chinstrap
male
199.91
5.98
0.18
2.50
Gentoo
female
212.71
3.90
0.22
2.62
Gentoo
male
221.54
5.67
-0.11
2.35
Como se aprecia con este caso, es frecuente que las variables de interés puedan ser aproximadas utilizando un único descriptor, por ejemplo, podemos estimar el tamaño de la aleta (variable continua) de los pingüinos de la especie Pygoscelis papua (población objetivo) midiendo la longitud en cm (descriptor) de cada pingüino (objeto). En este ejemplo, el tamaño es una variable unidimensional, ya que fue suficiente un único descriptor para aproximar las magnitudes de cambio en la variable. Sin embargo, hay variables que difícilmente puedan ser representadas por un único descriptor, y se requieren de varios a muchos descriptores para caracterizarla. Por ejemplo, para describir la dieta (variable) de los pingüinos juveniles de la especie P. papua (población objetivo) se deben analizar el material del contenido estomacal de individuos adultos luego del viaje de alimentación para sus polluelos figura 1.6, es decir, estimar la identidad y cantidad de cada ítem alimenticio (varios descriptores, uno por cada ítem) de cada pingüino (Lescroël, Ridoux, y Bost 2004). La dieta, como variable, es multidimensional, ya que se requerirá de múltiples descriptores para definir la expresión de la variable. En el contexto de este libro nos centraremos en variables respuesta que necesitan ser definidas por múltiples descriptores, y que llamaremos variables multidimensionales o multivariadas.
Fig. 1.6: Pingüino de Genttoo (Pygoscelis papua) alimentando a su polluelo con material regurgitado luego de un viaje de alimentación. Crédito de imagen dgwildlife
Guerra-Castro, Edlin J., Juan Carlos Cajas, Nuno Simões, Juan J. Cruz-Motta, y Maite Mascaró. 2021. «SSP: an R package to estimate sampling effort in studies of ecological communities». Journal Article. Ecography 44 (4): 561-73. https://doi.org/https://doi.org/10.1111/ecog.05284.
Horst, Allison Marie, Alison Presmanes Hill, y Kristen B Gorman. 2020. palmerpenguins: Palmer Archipelago (Antarctica) penguin data. https://doi.org/10.5281/zenodo.3960218.
Lescroël, A., V. Ridoux, y C. Bost. 2004. «Spatial and temporal variation in the diet of the gentoo penguin (Pygoscelis papua) at Kerguelen Islands». Journal Article. Polar Biology 27: 206-16. https://doi.org/10.1007/s00300-003-0571-3.
Smith, Adam N. H., Marti J. Anderson, y Matthew D. M. Pawley. 2017. «Could ecologists be more random? Straightforward alternatives to haphazard spatial sampling». Journal Article. Ecography, n/a-. https://doi.org/10.1111/ecog.02821.
Underwood, A. J. 1990. «Experiments in ecology and management: Their logics, functions and interpretations». Journal Article. Australian Journal of Ecology 15: 365-89.