Existe el interés de explorar como cambian las condiciones abióticas del agua en distintas localidades de la costa nor-occidental de México, con la finalidad de explorar potenciales relaciones entre dichas variables, así como la similitud entre distintas localidades con base en sus condiciones abióticas. Las variables fueron: temperatura (°C), salinidad (ups), pH, oxígeno disuelto (mg/l), clorofila (mg/m\(^3\)), nitrito (mg/l). Los datos se encuentran en la pestaña ‘abiot’ del archivo ‘datosIAM.xlsx’.
Importa los datos registrados, copiando el siguiente código. Identifica qué hace cada línea de comando. Examina el objeto que creaste y responde a las siguientes preguntas:
¿Cuántos descriptores están siendo usados para caracterizar las 6 localidades?
¿Son similares las escalas (y unidades) en las que están siendo medidas las variables abióticas? Explica.
Aplica la función summary sobre el objeto dat y describe lo que obtienes. ¿Sirve esta información resumida para comprender cómo se correlacionan unas variables con otras?
Copia el siguiente código para trasponer la matriz dat, y aplica la función summary sobre la nueva matriz dat.t. ¿Sirve esta información para comparar las localidades?
V1 V2 V3 V4
Min. : 0.153 Min. : 0.163 Min. : 0.165 Min. : 0.190
1st Qu.: 5.982 1st Qu.: 5.827 1st Qu.: 3.703 1st Qu.: 3.125
Median :17.960 Median :11.810 Median : 10.130 Median : 10.070
Mean :25.555 Mean :23.425 Mean : 59.074 Mean : 57.787
3rd Qu.:34.130 3rd Qu.:25.953 3rd Qu.: 21.312 3rd Qu.: 21.005
Max. :75.750 Max. :82.270 Max. :307.420 Max. :300.930
V5 V6
Min. : 0.008 Min. : 0.011
1st Qu.: 2.625 1st Qu.: 2.623
Median : 6.780 Median : 6.740
Mean :12.861 Mean :12.862
3rd Qu.:22.650 3rd Qu.:22.670
Max. :34.420 Max. :34.450
A partir de la observación detenida de ‘dat’, ¿puedes saber si algunas localidades están caracterizadas por ciertos valores de las variables (por ejemplo, salinidad alta, temp baja)?
Usa la función stack para apilar la columnas (valores de variables) unas encima de otras. Esto te permitirá elaborar gráficas usando la función qplot (del paquete ggplot2) con la información contenida en dat. Para ello corre el código y sigue estas intrucciones:
Código
#|eval: falselibrary(ggplot2)dat.s <-data.frame(stack(dat), loc =row.names(dat))
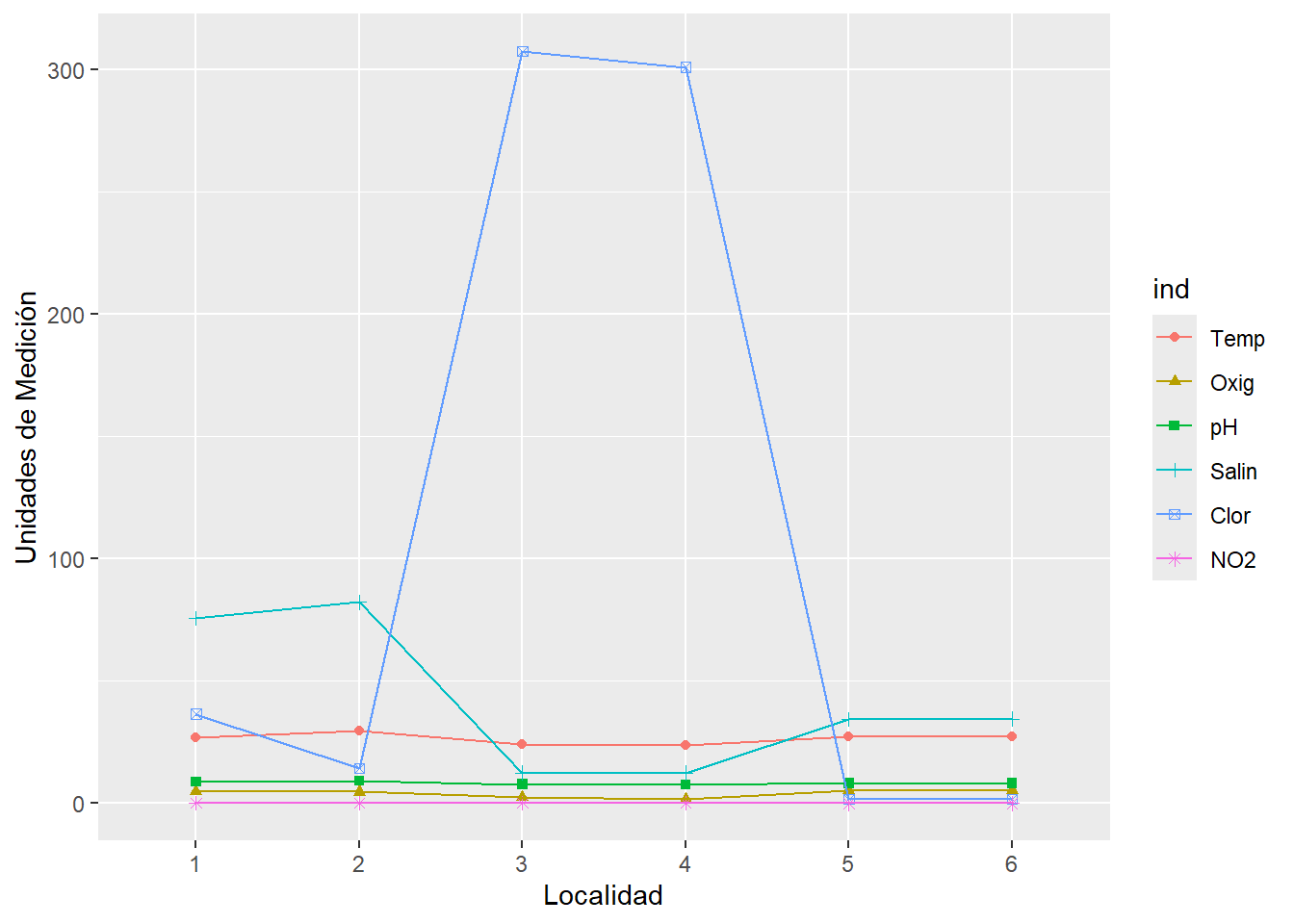
Examina el objeto dat.s y describe a qué se refiere ind, values y loc.
Copia el siguiente código e interpreta la gráfica de salida ¿Qué puedes decir sobre las diferencias en los valores de las variables para las distintas localidades? ¿Hay variables que varían conjuntamente?
Warning: `qplot()` was deprecated in ggplot2 3.4.0.
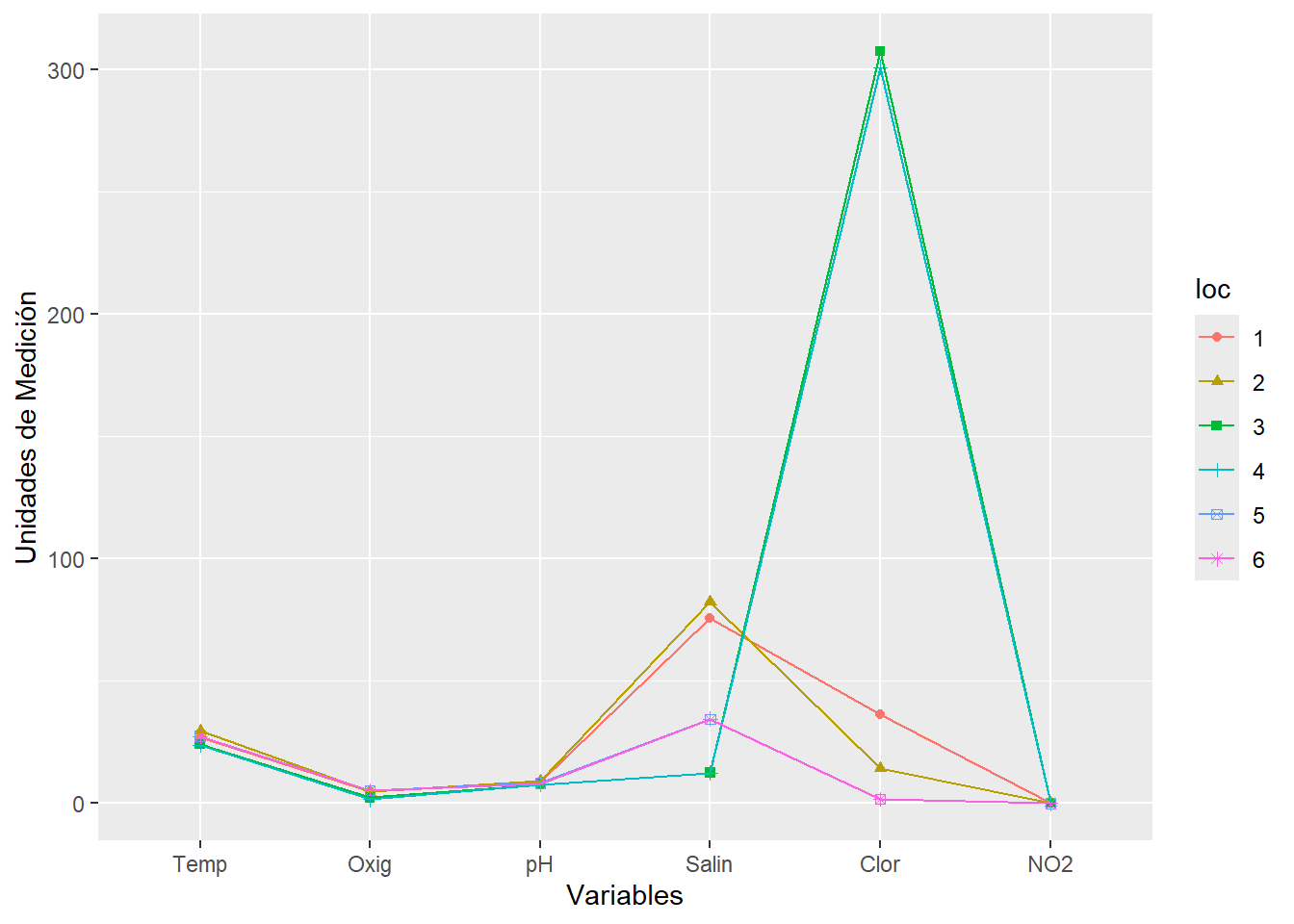
Copia ahora el siguiente código e interpreta esta segunda gráfica. ¿Qué puedes decir sobre las diferencias entre localidades?¿Hay localidades que se parecen entre si por los valores de sus variables?
¿Cómo harías un resúmen de la información numérica y gráfica obtenida hasta ahora? ¿Puedes responder a alguna de las preguntas de los investigadores?
Si obtuvieras una matriz con los valores de covariación entre todas las variables abióticas, considerando los valores en las 6 localidades:
¿Cuántas columnas y filas tendría dicha matriz? ¿Qué forma tendría?
¿Qué habría en la diagonal?
Obtén ésta matriz de covariación usando la función cov y verifica tus respuestas.
¿Cuáles son las variables que se correlacionan directamente y cuáles los hacen inversamente? ¿Cuáles son las que están más fuertemente asociadas? Para ello usa la función cor.
Aplica la función pairs a la matriz de correlaciones, y examina el resultado gráfico. ¿Cuáles son las unidades de los ejes en los gráficos obtenidos?
9.2 Medidas de distancias
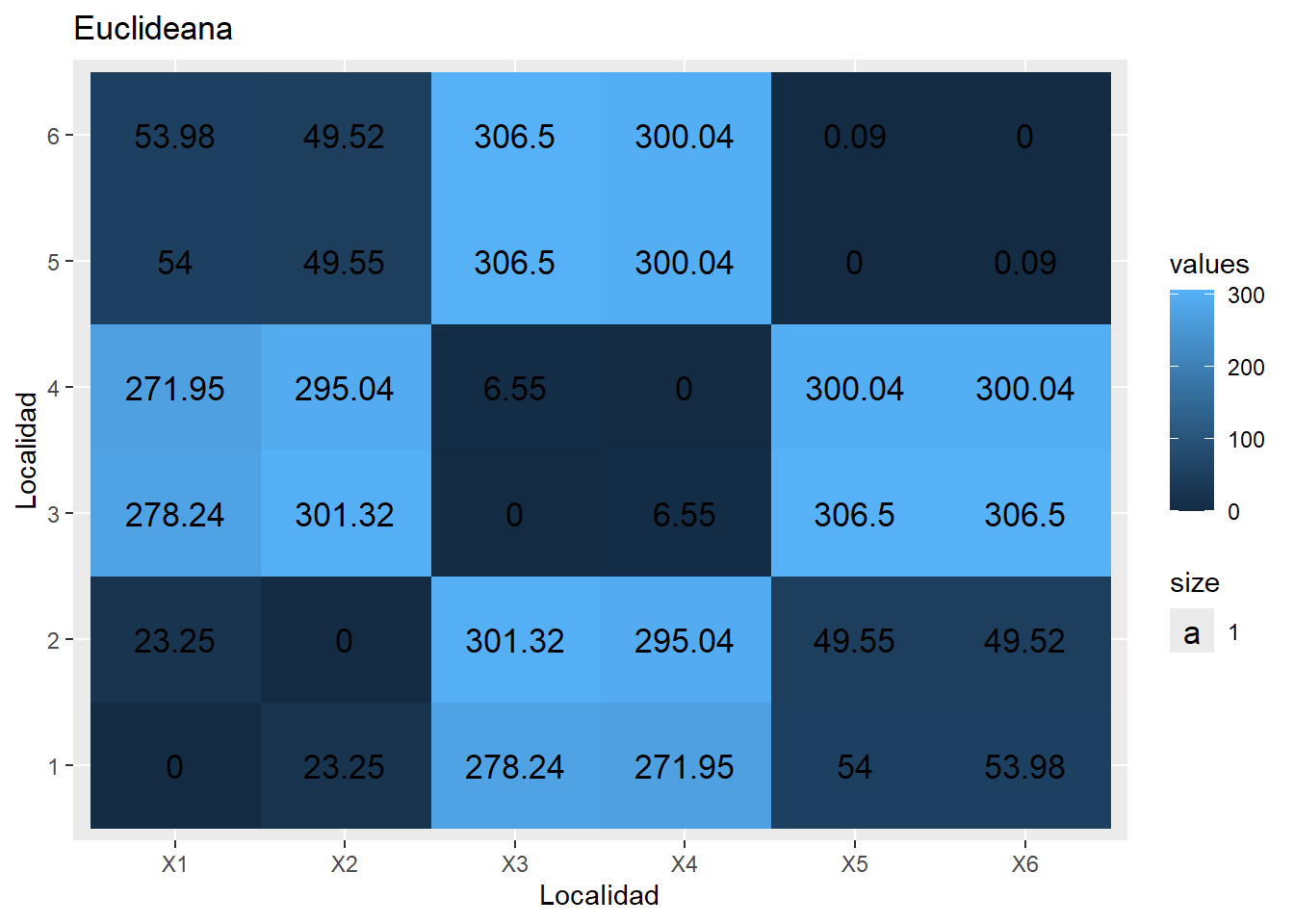
Obtén una matriz con las medidas de distancia Euclidiana entre todas las localidades considerando los valores de las 6 variables abióticas. Usa la función dist del paquete stats e identifica qué ocurre en cada una de las tres línea de comando.
¿qué ocurre en cada una de las tres línea de comando?
¿Cuántas columnas y filas tiene la matriz? ¿Qué forma tienen?
¿Qué hay en la diagonal?
¿Puedes decir qué localidades son las más y las menos similares entre si?
Si aplicas la función sort al objeto resultante de dist puedes ordenar estos datos en una escala de distancia euclideana ¿Sirve esto a tu propósito de describir resumidamente las diferencias entre localidades?
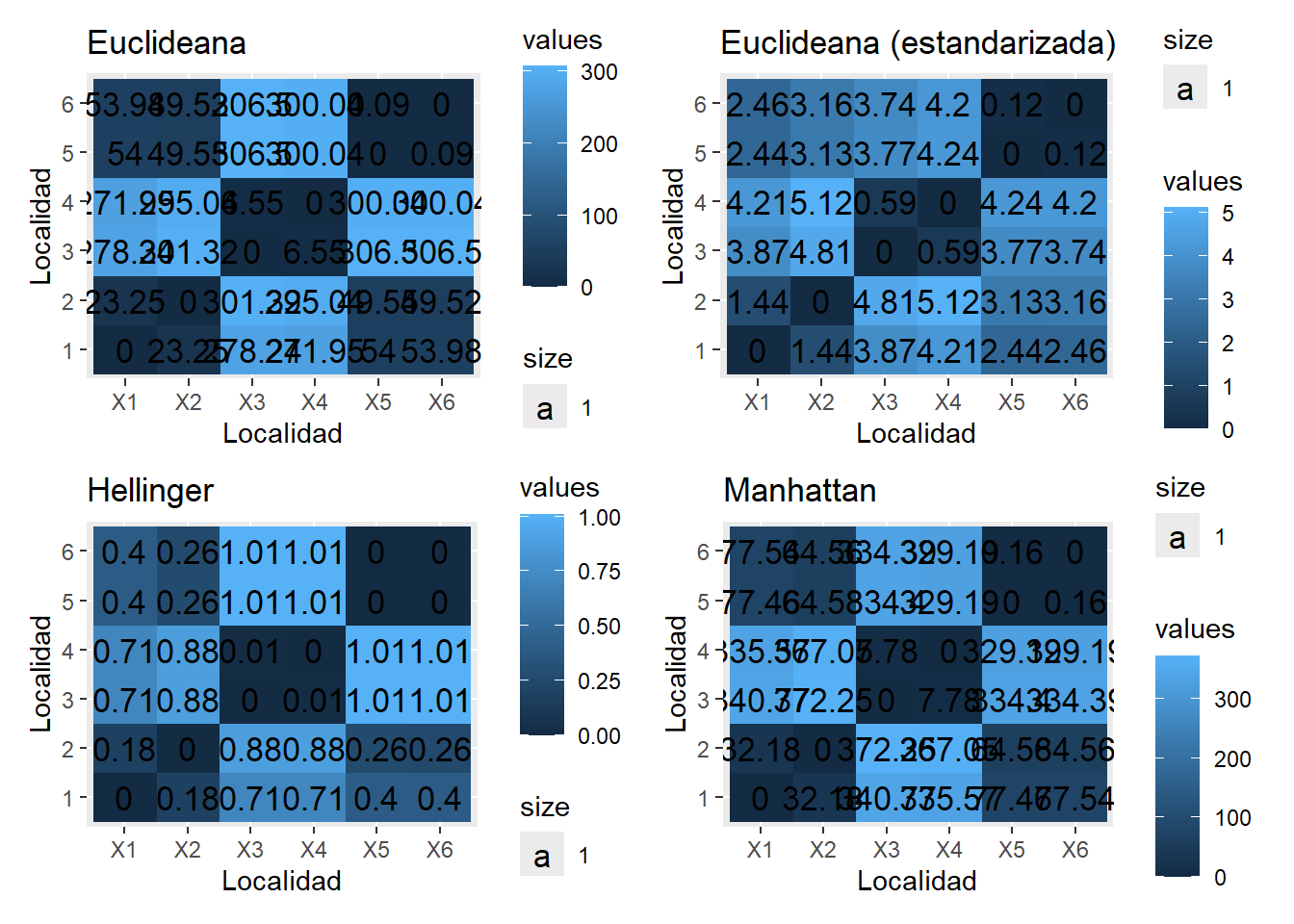
Copia el siguiente código para elaborar una gráfica tipo raster de la matriz de distancias euclideanas
¿Qué ganaste con esta gráfica en términos de la descripción de los datos abióticos?
Tomando en cuenta la información del objeto dat, identifica la variable que tiene más preponderancia para hacer que dos localidades se parezcan (o distingan). Explica tu respuesta.
¿Consideras que la distancia euclideana representa con fidelidad qué tanto se parecen 2 localidades por sus condiciones abióticas?
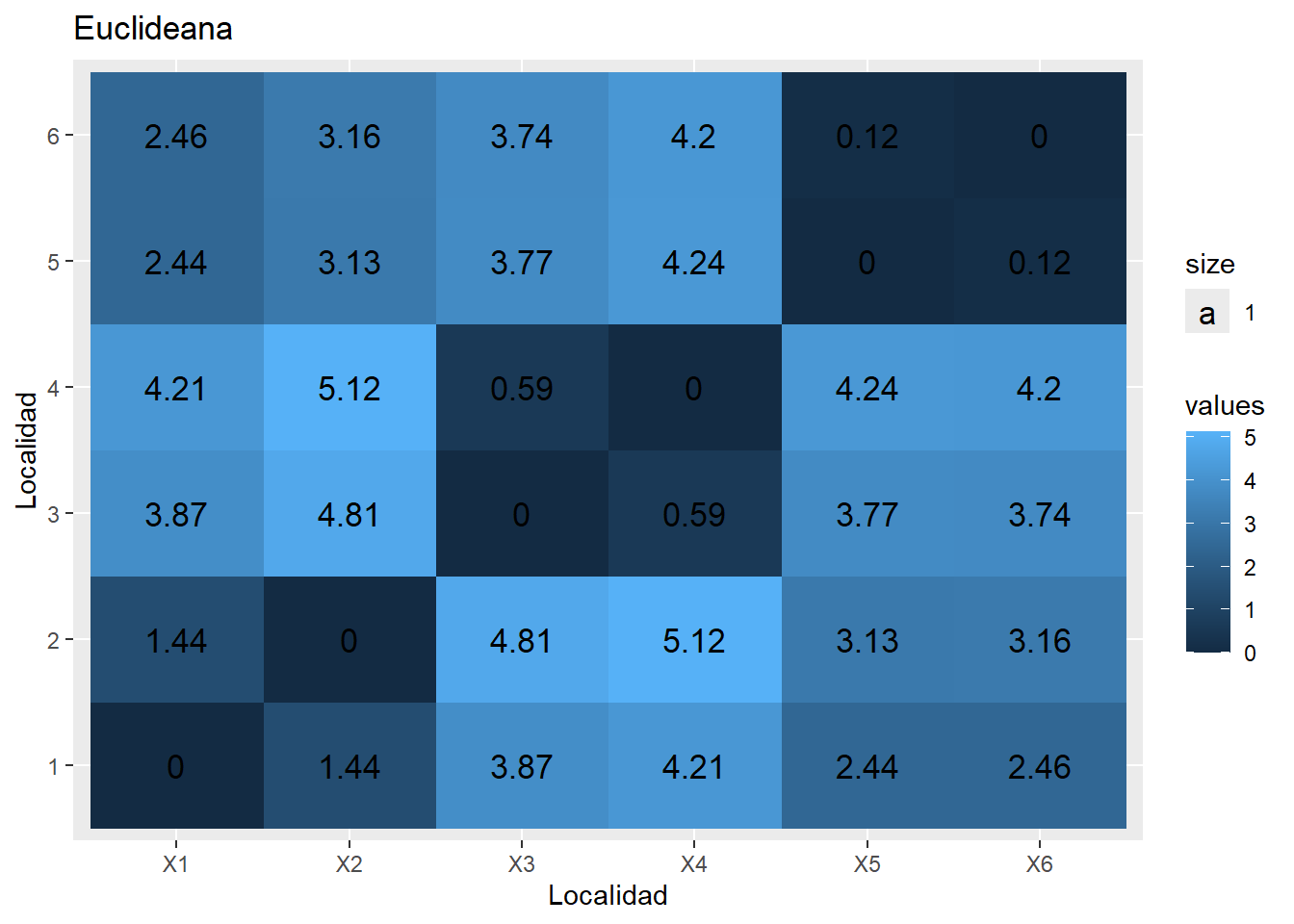
Para ver el efecto de una estandarización de las variables sobre la distancia euclideana, aplica la función decostand de vegan siguiendo el código a continuación. El argumento standardize transforma cada medición en z-scores (ésta centra y divide entre desviación estandar) para volver las medidas comparables.
Elabora el gráfico raster con la matriz de DE transformada, sustituyendo los nombres de los objetos en el código del numeral 5, y compara ambas gráficas. ¿Qué cambió?
¿Cual de las dos formas de resumir la información te parece más realista?
Para ver el efecto de distintas medidas de asociación sobre estos datos ambientales, obtén las distancias de Hellinger y Manhattan, a partir de la matriz dat y compara las matrices triangulares con la de DE.stan. Nota: para obtener la transformación de Hellinger, se aplica decostand a la matriz dat previo a obtener la euclideana. Si tienes dificultades usa la función help.
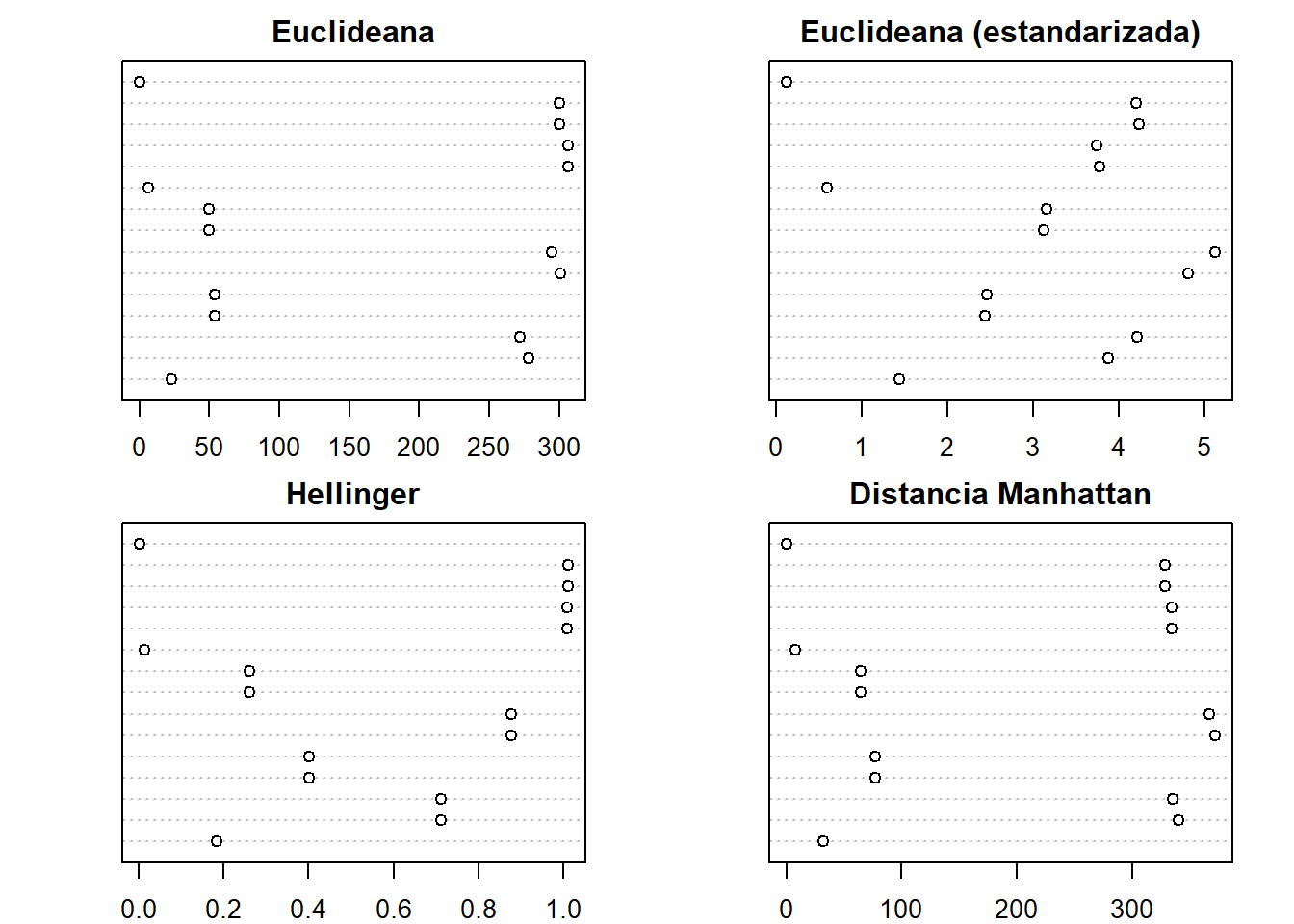
Copia el siguiente código para comparar los valores de las medidas usadas en esta actividad en términos de sus escalas relativas. ¿Cuáles fueron las diferencias y similitudes en la escala entre estas medidas de asociación?
Código
#|eval: falsepar(mfrow =c(2, 2), mar =c(2, 4, 2, 2))dotchart(as.vector(DE), main ="Euclideana")dotchart(as.vector(DE.stan), main ="Euclideana (estandarizada)")dotchart(as.vector(DH), main ="Hellinger")dotchart(as.vector(DM), main ="Distancia Manhattan")
Código
par(mfrow =c(1, 1))
Obtén las gráficas raster con base en las 4 medidas de asociación usadas en esta actividad para apoyar tu exploración. ¿Cuáles fueron las diferencias y similitudes en el agrupamiento de las localidades usando las distintas medidas de asociación?